One-Hot-Encoder1

رمزگذاری دسته بندی شده با استفاده از Label-Encoding و One-Hot-Encoder
در بسیاری از فعالیت های یادگیری ماشینی یا علم داده، مجموعه داده ها ممکن است حاوی متن یا مقادیر دسته بندی شده (به طور کلی مقادیر غیر عددی) باشد. به عنوان مثال، ویژگی رنگ دارای مقادیری مانند قرمز، نارنجی، آبی، سفید و غیره است. برنامه غذایی دارای مقادیری مانند صبحانه، ناهار، میان وعده ها، شام، چای و غیره است. الگوریتم های کمی مانند CATBOAST، درختان-تصمیم گیری می توانند مقادیر دسته بندی شده را به خوبی مدیریت کنند، اما بسیاری از الگوریتم ها انتظار دارند مقادیر عددی به نتایج جدید دست یابند.
در منحنی یادگیری شما در هوش مصنوعی و یادگیری ماشینی، یک نکته را متوجه خواهید شد که بیشتر الگوریتم ها با ورودی های عددی بهتر کار می کنند. بنابراین، چالش اصلی که یک تحلیلگر با آن مواجه است، تبدیل داده های متنی / دسته ای به داده های عددی و ایجاد الگوریتم / مدلی است که از آن معنا پیدا کند. شبکه های عصبی، که پایه یادگیری عمیق هستند، انتظار دارند مقادیر ورودی عددی باشند.
روش های زیادی برای تبدیل مقادیر دسته بندی شده به مقادیر عددی وجود دارد. هر رویکرد دارای معاوضه ها و تأثیرات خاص خود بر مجموعه ویژگی ها است. بدینوسیله، در این مقاله بر روی 2 روش اصلی تمرکز خواهیم کرد: One Hot Encoding و Label Encoder. هر دوی این رمزگذار ها بخشی از کتابخانه SciKit-learn (یکی از پرکاربرد ترین کتابخانه های پایتون) هستند و برای تبدیل متن یا داده های دسته بندی به داده های عددی که مدل انتظار دارد و عملکرد بهتری با آن دارد، استفاده می شوند.
تکه های کد در این مقاله از پایتون هستند.
Label Encoding
این روش بسیار ساده است و شامل تبدیل هر مقدار در یک ستون به یک عدد است. مجموعه داده ای از پل ها را در نظر بگیرید که دارای ستونی هستند، انواع پل ها را با مقادیر زیر نام گذاری می کنند. اگر چه ستون های بیشتری در مجموعه داده وجود خواهد داشت، برای درک label encoding، ما فقط بر روی یک ستون طبقه بندی شده تمرکز می کنیم.
BRIDGE-TYPE
Arch
Beam
Truss
Cantilever
Tied Arch
Suspension
Cable
انتخاب ما این است که مقادیر متن را با قرار دادن یک دنباله در حال اجرا برای هر مقدار متن مانند زیر رمزگذاری کنیم:
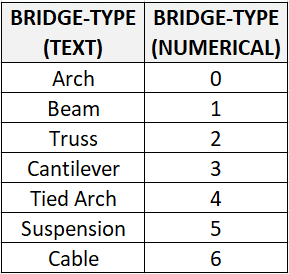
با این کار، label-encoding نوع پل متغیر را تکمیل کردیم. تمام label-encoding مربوط به انجام این کار است. اما بسته به مقادیر داده ها و نوع داده، label-encoding مشکل جدیدی ایجاد می کند زیرا از ترتیب اعداد استفاده می کند. مشکل استفاده از عدد این است که آنها رابطه / مقایسه بین خود را را معرفی می کنند. ظاهرا بین انواع پل، ارتباطی وجود ندارد، اما با نگاه به عدد، ممکن است تصور شود که نوع پل “کابلی” (Cable bridge type) نسبت به نوع پل “آرچ یا قوسی” (Arch bridge type) ارجحیت بیشتری دارد. این الگوریتم ممکن است به اشتباه متوجه شود که داده ها دارای نوعی سلسله مراتب / ترتیب 0 < 1 < 2 … < 6 هستند و ممکن است مقدار وزن 6 برابر بیشتری به پل “کابل” در محاسبه، نسبت به نوع پل “قوسی” بدهد.
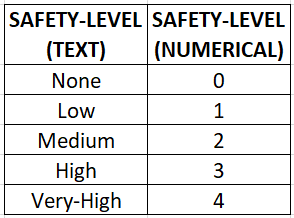
بیایید ستون دیگری را تحت عنوان “سطح ایمنی” در نظر بگیریم. انجام label-encoding بر این ستون نیز باعث ایجاد ترتیب / اولویت در تعداد؛ اما به روش صحیح می شود. در اینجا ترتیب عددی خارج از چارچوب به نظر نمی رسد و منطقی است اگر الگوریتم ترتیب ایمنی 0 < 1 < 2 < 3 < 4 یا به عبارت دیگر none < low < medium < high < very high را تفسیر کند.
Label-Encoding در پایتون
با استفاده از رویکرد کد های دسته بندی شده:
این رویکرد مستلزم آن است که ستون دسته از نوع داده «دسته» باشد. به طور پیش فرض، یک ستون غیر عددی از نوع “هدف (object)” است. بنابراین ممکن است لازم باشد قبل از استفاده از این روش، نوع را به «دسته» تغییر دهید.
# import required libraries
import pandas as pd
import numpy as np# creating initial dataframe
bridge_types = (‘Arch’,’Beam’,’Truss’,’Cantilever’,’Tied Arch’,’Suspension’,’Cable’)
bridge_df = pd.DataFrame(bridge_types, columns=[‘Bridge_Types’])# converting type of columns to ‘category’
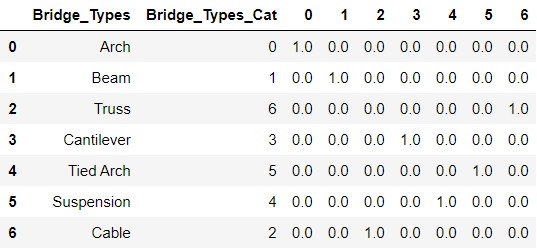
bridge_df[‘Bridge_Types’] = bridge_df[‘Bridge_Types’].astype(‘category’)# Assigning numerical values and storing in another column
bridge_df[‘Bridge_Types_Cat’] = bridge_df[‘Bridge_Types’].cat.codes
bridge_df
با استفاده از روش کتابخانه SicKit-Learn:
روش رایج دیگری که بسیاری از تحلیلگران داده label-encoding را به استفاده از آن انجام می دهند، استفاده از کتابخانه-learn SciKit است.
import pandas as pd
import numpy as np
from sklearn.preprocessing import LabelEncoder
# creating initial dataframe
bridge_types = (‘Arch’,’Beam’,’Truss’,’Cantilever’,’Tied Arch’,’Suspension’,’Cable’)
bridge_df = pd.DataFrame(bridge_types, columns=[‘Bridge_Types’])
# creating instance of labelencoder
labelencoder = LabelEncoder()
# Assigning numerical values and storing in another column
bridge_df[‘Bridge_Types_Cat’] = labelencoder.fit_transform(bridge_df[‘Bridge_Types’])
bridge_df
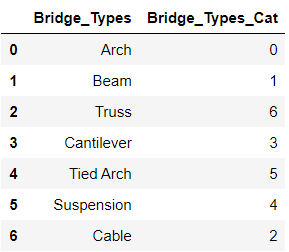
bridge_df با مقادیر ستونی دسته بندی شده و ستون هایlabel-encoded
One-Hot Encoder
اگرچه label-encoding مستقیم است، اما این عیب را دارد که مقادیر عددی را می توان به طور اشتباه توسط الگوریتم ها به عنوان داشتن نوعی سلسله مراتب / ترتیب در آنها تعبیر کرد. این مسئله سفارش، در یک رویکرد جایگزین رایج دیگر به نام “One Hot Encoding” بررسی می شود. در این استراتژی، هر مقدار دسته، به یک ستون جدید تبدیل می شود و یک مقدار 1 یا 0 (نماد درست / نادرست) به ستون اختصاص می یابد. بیایید مثال قبلی از نوع پل و سطوح ایمنی را با استفاده از یک one-hot encoder در نظر بگیریم.
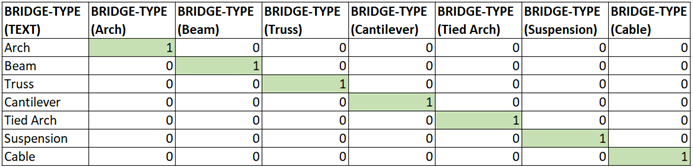
در بالا مقادیر one-hot encoded ستون طبقه بندی شده، “نوع-پل” وجود دارد. به همین شکل، بیایید ستون “سطح ایمنی” را بررسی کنیم.
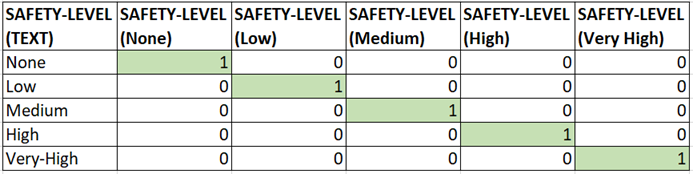
سطر هایی که دارای مقدار ستون اول (Arch / None) هستند دارای “1” (نشان دهنده درست) و سایر ستون ها دارای “0” (نشان دهنده نادرست) خواهند بود. به طور مشابه، برای ردیف های دیگر که مقدار را با مقدار ستون تطبیق می دهند.
اگرچه این رویکرد، مسائل مربوط به سلسله مراتب / ترتیب را حذف می کند، اما جنبه منفی اضافه کردن ستون های بیشتر به مجموعه داده را دارد. اگر مقادیر منحصر به فرد زیادی در یک ستون دسته بندی داشته باشید، می تواند باعث شود تعداد ستون ها به شدت افزایش یابد. در مثال بالا، قابل مدیریت بود، اما زمانی که کدگذاری ستون های زیادی را ارائه می کند، مدیریت آن بسیار چالش برانگیز خواهد بود.
One-Hot Encoding در پایتون
با استفاده از روش کتابخانه Scikit-Learn:
OneHotEncoder از کتابخانه SciKit فقط مقادیر مقوله ای عددی را می گیرد، بنابراین هر مقدار از نوع رشته باید قبل از کدگذاری One-Hot ، کدگذاری Label شود. بنابراین با استفاده از چارچوب داده از مثال قبلی، OneHotEncoder را در ستون Bridge_Types_Cat اعمال می کنیم.
import pandas as pd
import numpy as np
from sklearn.preprocessing import OneHotEncoder
# creating instance of one-hot-encoder
enc = OneHotEncoder(handle_unknown=’ignore’)
# passing bridge-types-cat column (label encoded values of bridge_types)
enc_df = pd.DataFrame(enc.fit_transform(bridge_df[[‘Bridge_Types_Cat’]]).toarray())
# merge with main df bridge_df on key values
bridge_df = bridge_df.join(enc_df)
bridge_df
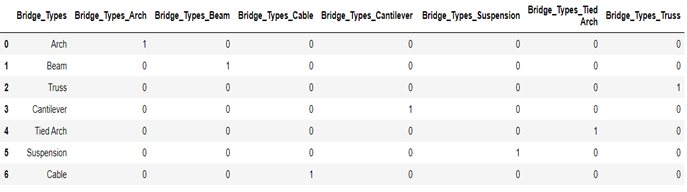
ستون Bridge_Type با استفاده از SciKit OneHotEncoder کدگذاری شده است
ستون های «Bridge_Types_Cat» را می توان از چارچوب داده حذف کرد.
استفاده از رویکرد مقادیر ساختگی:
این رویکرد انعطاف پذیرتر است؛ زیرا اجازه می دهد تا هر تعداد ستون دسته را که می خواهید رمزگذاری کنید و نحوه برچسبگذاری ستون ها را با استفاده از یک پیشوند انتخاب کنید. نامگذاری مناسب بقیه تجزیه و تحلیل را کمی آسان تر می کند.
import pandas as pd
import numpy as np
# creating initial dataframe
bridge_types = (‘Arch’,’Beam’,’Truss’,’Cantilever’,’Tied Arch’,’Suspension’,’Cable’)
bridge_df = pd.DataFrame(bridge_types, columns=[‘Bridge_Types’])
# generate binary values using get_dummies
dum_df = pd.get_dummies(bridge_df, columns=[“Bridge_Types”], prefix=[“Type_is”] )
# merge with main df bridge_df on key values
bridge_df = bridge_df.join(dum_df)
bridge_df
مقادیر Bridge_Type با استفاده از رویکرد ساختگی کدگذاری می شوند
نتیجه گیری
درک گزینه های مختلف برای رمزگذاری متغیر های طبقه بندی مهم است زیرا هر رویکرد مزایا و معایب خاص خود را دارد. در علم داده، این گام مهمی است، بنابراین من واقعا شما را تشویق می کنم که این ایده ها را هنگام برخورد با متغیر های طبقه بندی در ذهن داشته باشید./
دیدگاهتان را بنویسید