LSTM-02
مرور
این مقاله نحوه ایجاد یک دنباله پشتهای برای توالی بندی مدل LSTM برای پیش بینی سری های زمانی در Keras/TF 2.0 را مشاهده می کند.
پیش نیاز ها: خواننده باید از قبل با شبکه های عصبی و به ویژه شبکه های عصبی بازگشتی (RNN) آشنا باشد. همچنین آشنایی با مدل های LSTM یا GRU ارجحیت دارد. اگر با LSTM آشنایی ندارید، ترجیحا LSTM-Long Short-Term Memory را بخوانید.
مقدمه
در یادگیری توالی به ترتیب، یک مدل RNN برای نگاشت یک توالی ورودی به یک دنباله خروجی آموزش داده می شود. طول ورودی و خروجی لزوما یکسان نیست. مدل seq2seq شامل دو RNN است، به عنوان مثال، LSTM ها. آنها را می توان به عنوان یک رمز گذار و رمز گشا در نظر گرفت. بخش رمز گذار دنباله ورودی داده شده را به یک بردار با طول ثابت تبدیل می کند که به عنوان خلاصه ای از دنباله ورودی عمل می کند.
این بردار با طول ثابت، بردار زمینه نامیده می شود. بردار زمینه به عنوان ورودی به رمز گشا و حالت رمز گذار نهایی به عنوان حالت رمز گشای اولیه برای پیش بینی دنباله خروجی داده می شود. یادگیری Sequence to Sequence (یادگیری دنباله به ترتیب) در ترجمه زبان، تشخیص گفتار، سری های زمانی، پیش بینی و غیره استفاده می شود.
ما از دنباله برای یادگیری توالی برای پیش بینی سری های زمانی استفاده خواهیم کرد. ما می توانیم از این معماری برای پیش بینی چند مرحله ای به راحتی استفاده کنیم. ما دو لایه، که شامل یک لایه بردار تکرار شده و لایه متراکم توزیع شده در زمان را در معماری را اضافه خواهیم کرد.
یک لایه بردار تکرار شده برای تکرار بردار زمینه ای که از رمزگذار می گیریم استفاده می شود تا آن را به عنوان ورودی به رمزگشا منتقل کنیم. ما آن را به تعداد n گام تکرار می کنیم (n شماره گام های آینده است که می خواهید پیش بینی کنید.). خروجی دریافت شده از رمزگشایی با توجه به هر مرحله زمانی مخلوط می شود. زمان توزیع متراکم یک لایه متراکم کاملا متصل را روی هر مرحله زمانی اعمال می کند و خروجی را برای هر مرحله زمانی جدا می کند. زمان توزیع متراکم پوششی است که اجازه می دهد تا یک لایه را به هر برش موقتی یک ورودی اعمال کند.
ما لایه های اضافی را روی قسمت رمزگذار و بخش رمزگشای مدل دنباله به دنباله (sequence to sequence model) قرار می دهیم. با انباشته کردن LSTM، ممکن است توانایی مدل ما برای درک ارائه پیچیده تری از داده های سری زمانی ما در لایه های پنهان، با گرفتن اطلاعات در سطوح مختلف را افزایش دهد.
کد
داده های استفاده شده، مصرف برق خانگی فردی می باشد. می توانید این مجموعه داده را از این لینک دانلود کنید.
واردات کتابخانه ها
import pandas as pd
import numpy as np
from sklearn.preprocessing import MinMaxScaler
import matplotlib.pyplot as plt
import tensorflow as tf
import os
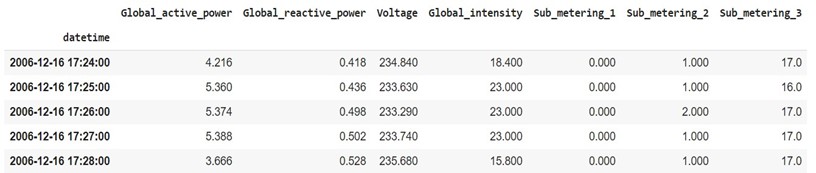
حال مجموعه داده را در یک چارچوب داده pandas بارگذاری کنید.
df=pd.read_csv(r’household_power_consumption.txt’, sep=’;’, header=0, low_memory=False, infer_datetime_format=True, parse_dates={‘datetime’:[0,1]}, index_col=[‘datetime’])
df.head()
وارد کردن مقادیر تهی
df = df.replace(‘?’, np.nan)
df.isnull().sum()

اکنون تابعی ایجاد می کنیم که مقادیر گم شده را با جایگزین کردن آنها با مقادیر در روز قبل به هم نسبت می دهد.
def fill_missing(values):
one_day = 60*24
for row in range(df.shape[0]):
for col in range(df.shape[1]):
if np.isnan(values[row][col]):
values[row,col] = values[row-one_day,col]
df = df.astype(‘float32’)
fill_missing(df.values)
df.isnull().sum()

کاهش نمونه داده ها از دقیقه به روز
بیش از حدود صد هزار (lakh: واحدی در سیستم شماره گذاری هند) مشاهدات ثبت شده است. بیایید داده ها را با کاهش تعداد دفعات چند دقیقه به چند روز ساده تر کنیم.
daily_df = df.resample(‘D’).sum()
daily_df.head()

جدا سازی آموزش – آزمایش
پس از کاهش تعداد نمونه داده ها، تعداد نمونه ها 1442 می باشد. ما مجموعه داده را به داده های آموزشی و آزمایشی در نسبت 75% و 25% از نمونه ها تقسیم می کنیم. (0.75 * 1442 = 1081).
train_df,test_df = daily_df[1:1081], daily_df[1081:]
مقیاس بندی مقادیر
تمام ستون ها در چارچوب داده در مقیاس متفاوتی هستند. اکنون برای آموزش سریعتر مدل ها، مقادیر را از منفی 1 به 1 مقیاس بندی می کنیم.
train = train_df
scalers={}
for i in train_df.columns:
scaler = MinMaxScaler(feature_range=(-1,1))
s_s = scaler.fit_transform(train[i].values.reshape(-1,1))
s_s=np.reshape(s_s,len(s_s))
scalers[‘scaler_’+ i] = scaler
train[i]=s_s
test = test_df
for i in train_df.columns:
scaler = scalers[‘scaler_’+i]
s_s = scaler.transform(test[i].values.reshape(-1,1))
s_s=np.reshape(s_s,len(s_s))
scalers[‘scaler_’+i] = scaler
test[i]=s_s
تبدیل سری ها به نمونه
اکنون تابعی خواهیم ساخت که از رویکرد پنجره لغزان (sliding window) برای تبدیل سری های ما به نمونه هایی از مشاهدات ورودی گذشته و خروجی مشاهدات آینده برای استفاده از الگوریتم های یادگیری نظارت شده استفاده می کند.
def split_series(series, n_past, n_future):
#
# n_past ==> no of past observations
#
# n_future ==> no of future observations
#
X, y = list(), list()
for window_start in range(len(series)):
past_end = window_start + n_past
future_end = past_end + n_future
if future_end > len(series):
break
# slicing the past and future parts of the window
past, future = series[window_start:past_end, :], series[past_end:future_end, :]
X.append(past)
y.append(future)
return np.array(X), np.array(y)
برای این مورد، فرض کنید با توجه به مشاهدات 10 روز گذشته، باید مشاهدات 5 روز آینده را پیش بینی کنیم.
n_past = 10
n_future = 5
n_features = 7
اکنون با استفاده از تابع split_series هم داده های آموزشی و هم داده های آزمایشی را به نمونه تبدیل کنید.
X_train, y_train = split_series(train.values,n_past, n_future)
X_train = X_train.reshape((X_train.shape[0], X_train.shape[1],n_features))
y_train = y_train.reshape((y_train.shape[0], y_train.shape[1], n_features))
X_test, y_test = split_series(test.values,n_past, n_future)
X_test = X_test.reshape((X_test.shape[0], X_test.shape[1],n_features))
y_test = y_test.reshape((y_test.shape[0], y_test.shape[1], n_features))
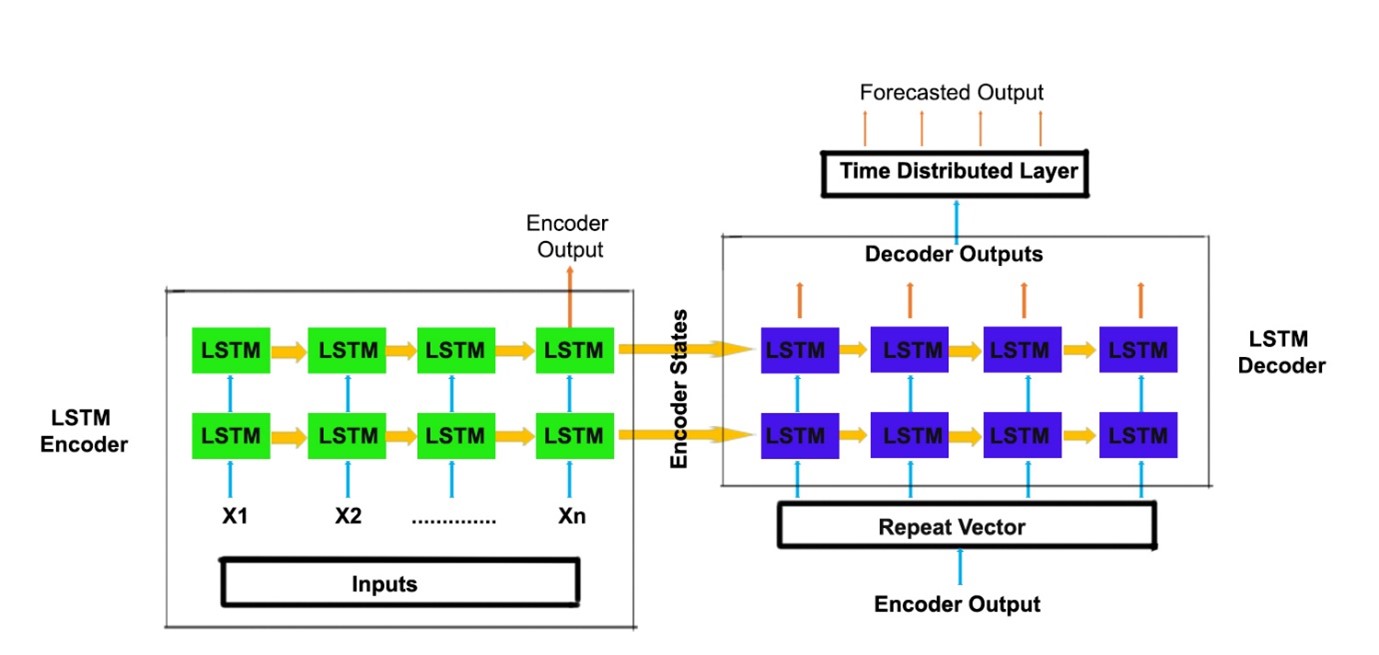
معماری مدل
اکنون دو مدل در معماری ذکر شده در زیر را ایجاد می کنیم.
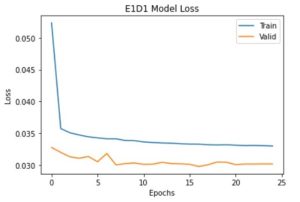
E1D1 ==> Sequence to Sequence Model with one encoder layer and one decoder layer.
(مدل دنباله به دنباله با یک لایه رمز گذار و یک لایه رمز گشا)
# E1D1
# n_features ==> no of features at each timestep in the data.
#
encoder_inputs = tf.keras.layers.Input(shape=(n_past, n_features))
encoder_l1 = tf.keras.layers.LSTM(100, return_state=True)
encoder_outputs1 = encoder_l1(encoder_inputs)
encoder_states1 = encoder_outputs1[1:]
#
decoder_inputs = tf.keras.layers.RepeatVector(n_future)(encoder_outputs1[0])
#
decoder_l1 = tf.keras.layers.LSTM(100, return_sequences=True)(decoder_inputs,initial_state = encoder_states1)
decoder_outputs1 = tf.keras.layers.TimeDistributed(tf.keras.layers.Dense(n_features))(decoder_l1)
#
model_e1d1 = tf.keras.models.Model(encoder_inputs,decoder_outputs1)
#
model_e1d1.summary()

E2D2 ==> Sequence to Sequence Model with two encoder layers and two decoder layers.
(مدل دنباله به دنباله با دو لایه رمز گذار و دو لایه رمز گشا)
# E2D2
# n_features ==> no of features at each timestep in the data.
#
encoder_inputs = tf.keras.layers.Input(shape=(n_past, n_features))
encoder_l1 = tf.keras.layers.LSTM(100,return_sequences = True, return_state=True)
encoder_outputs1 = encoder_l1(encoder_inputs)
encoder_states1 = encoder_outputs1[1:]
encoder_l2 = tf.keras.layers.LSTM(100, return_state=True)
encoder_outputs2 = encoder_l2(encoder_outputs1[0])
encoder_states2 = encoder_outputs2[1:]
#
decoder_inputs = tf.keras.layers.RepeatVector(n_future)(encoder_outputs2[0])
#
decoder_l1 = tf.keras.layers.LSTM(100, return_sequences=True)(decoder_inputs,initial_state = encoder_states1)
decoder_l2 = tf.keras.layers.LSTM(100, return_sequences=True)(decoder_l1,initial_state = encoder_states2)
decoder_outputs2 = tf.keras.layers.TimeDistributed(tf.keras.layers.Dense(n_features))(decoder_l2)
#
model_e2d2 = tf.keras.models.Model(encoder_inputs,decoder_outputs2)
#
model_e2d2.summary()

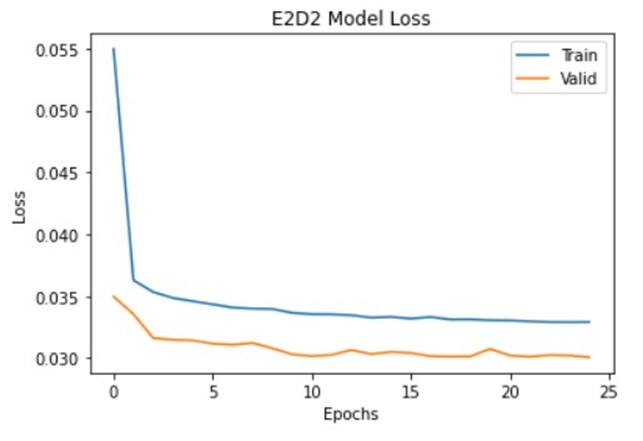
آموزش مدل ها
من از Adam optimizer و Huber loss به عنوان تابع ضرر استفاده کرده ام. بیایید مدل را جمع آوری و اجرا کنیم.
reduce_lr = tf.keras.callbacks.LearningRateScheduler(lambda x: 1e-3 * 0.90 ** x)
model_e1d1.compile(optimizer=tf.keras.optimizers.Adam(), loss=tf.keras.losses.Huber())
history_e1d1=model_e1d1.fit(X_train,y_train,epochs=25,validation_data=(X_test,y_test),batch_size=32,verbose=0,callbacks=[reduce_lr])
model_e2d2.compile(optimizer=tf.keras.optimizers.Adam(), loss=tf.keras.losses.Huber())
history_e2d2=model_e2d2.fit(X_train,y_train,epochs=25,validation_data=(X_test,y_test),batch_size=32,verbose=0,callbacks=[reduce_lr])
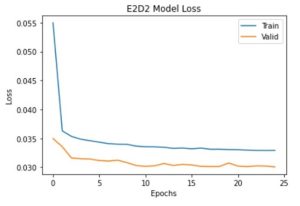
پیش بینی بر روی نمونه های آزمایشی
pred_e1d1=model_e1d1.predict(X_test)
pred_e2d2=model_e2d2.predict(X_test)
مقیاس بندی معکوس مقادیر پیش بینی شده
اکنون پیش بینی ها را به مقیاس اصلی خود تبدیل می کنیم.
for index,i in enumerate(train_df.columns):
scaler = scalers[‘scaler_’+i]
pred1_e1d1[:,:,index]=scaler.inverse_transform(pred1_e1d1[:,:,index])
pred_e1d1[:,:,index]=scaler.inverse_transform(pred_e1d1[:,:,index])
pred1_e2d2[:,:,index]=scaler.inverse_transform(pred1_e2d2[:,:,index])
pred_e2d2[:,:,index]=scaler.inverse_transform(pred_e2d2[:,:,index])
y_train[:,:,index]=scaler.inverse_transform(y_train[:,:,index])
y_test[:,:,index]=scaler.inverse_transform(y_test[:,:,index])
بررسی خطا
اکنون میانگین خطای مطلق همه مشاهدات را محاسبه می کنیم.
from sklearn.metrics import mean_absolute_error
for index,i in enumerate(train_df.columns):
print(i)
for j in range(1,6):
print(“Day “,j,”:”)
print(“MAE-E1D1 : “,mean_absolute_error(y_test[:,j-1,index],pred1_e1d1[:,j-1,index]),end=”, “)
print(“MAE-E2D2 : “,mean_absolute_error(y_test[:,j-1,index],pred1_e2d2[:,j-1,index]))
print()
print()
از خروجی بالا می توان مشاهده کرد که در برخی موارد مدل E2D2 با خطای کمتری نسبت به مدل E1D1 عملکرد بهتری داشته است. آموزش مدل های مختلف با تعداد لایه های انباشته متفاوت و ایجاد یک مدل مجموعه (جامع یا کلی) نیز عملکرد خوبی دارد.
توجه: نتایج با توجه به مجموعه داده متفاوت است. اگر لایه های بیشتری را روی هم قرار دهیم، ممکن است به ب رازش بیش از حد نیز منجر شود. بنابراین تعداد لایه هایی که قرار است روی هم چیده شوند به عنوان یک هایپر پارامتر (فرا پارامتر) عمل می کند./
دیدگاهتان را بنویسید