RNN

مقدمه
ما یک لایه ورودی، یک لایه پنهان و یک لایه خروجی داریم. لایه ورودی، ورودی را می گیرد، توابع فعال سازی به لایه پنهان اعمال می شوند؛ و در نهایت خروجی را دریافت می کنیم.
در یک شبکه عصبی عمیق چندین لایه پنهان وجود دارد. هر لایه پنهان با وزن ها و سوگیری هایش شناخته می شود.
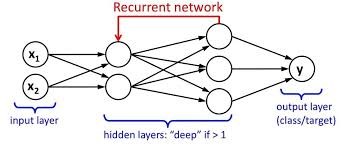
وزن و سوگیری این لایه های پنهان متفاوت است. از این رو هر یک از این لایه ها رفتار متفاوت/ مستقلی دارند؛ به طوری که نتوانیم آن ها را با هم ترکیب کنیم. ما باید همان وزن ها و سوگیری ها را برای این لایه های پنهان داشته باشیم تا این لایه های پنهان را به هم پیوند دهند.
حال میتوانیم این لایه ها را با هم ترکیب کنیم، زیرا وزن و جهت همه لایه های پنهان در حال حاضر یکسان است. همه این لایه های پنهان را می توان در یک لایه بازگشتی به هم متصل کرد.
سه نوع شبکه عصبی عمیق وجود دارد:
- شبکه عصبی مصنوعی
- شبکه عصبی پیچشی یا کانولوشنال
- شبکه عصبی بازگشتی
در این مقاله، به شبکه های عصبی بازگشتی می پردازیم.
RNN ها چیست؟
- مجموعه ای از شبکه های عصبی پیش خور که در آن گره های پنهان به صورت سلسله ای به هم متصل می شوند.
- RNN برخلاف CNN دارای پیش بینی های سری متعدد است.
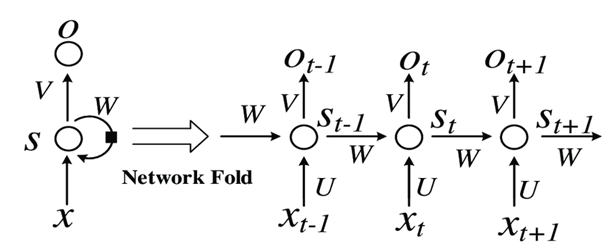
منبع تصویر:
انواع RNN ها
- یک به یک: به این شبکه عصبی، وانیلی نیز گفته می شود. RNN یک به یک، در چنین مشکلات یادگیری ماشینی که دارای یک ورودی و یک خروجی هست.
- یک به چند: دارای یک ورودی و چند خروجی است. به عنوان مثال می توان به موسیقی|نسل اشاره کرد.
- چند به یک: RNN دنباله ای از ورودی ها را می گیرد و یک خروجی واحد تولید می کند.
- چند به چند: RNN دنباله ای از ورودی ها را می گیرد و دنباله ای از خروجی ها را تولید می کند. به عنوان مثال، ترجمه زبان.
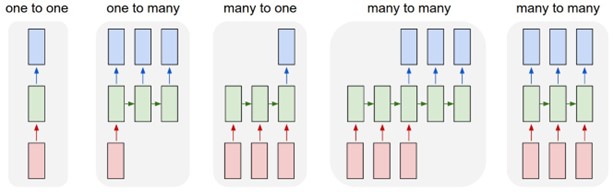
منبع تصویر: https://i.stack.imgur.com/6VAOt.jpg
پیشرفت RNN:
- RNN ها مشکلی به نام ناپدید شدن گرادیان (طیف) نزولی دارند.
- از این رو دو پیشرفت نسبت به آن وجود دارد:
- واحد بازگشتی دردار یا محصور (GRU)
- حافظه کوتاه مدت و بلند مدت (LSTM)
– در میان این موارد، LSTM محبوب تر است و نیز بیشتر در پیش بینی سری های زمانی استفاده می شود.
مشکل محو شدن گرادیان
قبل از اینکه اولین RNN خود را بسازیم، باید مشکل محو شدن گرادیان را درک کنیم. بیایید نگاهی گذرا به مشکل محو شدن گرادیان بیندازیم.
مشکل محو شدن گرادیان چیست؟
مسئله محو شدن گرادیان توسط سپ هوکرایتر (Sepp Hochreiter)؛ دانشمند کامپیوتر آلمانی که نیز نقشی در توسعه شبکه های عصبی بازگشتی در یادگیری عمیق داشت.
همانطور که از نام آن مشخص است، مشکل محو شدن گرادیان مربوط به الگوریتم های گرادیان نزولی یادگیری عمیق است. الگوریتم گرادیان نزولی سپس با یک الگوریتم پس انتشار ترکیب می شود تا وزن ها را در سراسر شبکه عصبی به روز کند. شبکه عصبی بازگشتی به علت لایه پنهان یک مشاهده که برای آموزش لایه پنهان مشاهده بعدی استفاده می شود، کمی متفاوت رفتار می کند.
مشکل محو شدن گرادیان زمانی اتفاق میافتد که الگوریتم پس انتشار از طریق تمام نورونهای شبکه عصبی برای به روز رسانی وزن خود به عقب برگردد.
مقدار دهی اولیه وزن ها یکی از تکنیک هایی است که می توان برای حل مسئله محو شدن گرادیان استفاده کرد. که شامل ایجاد یک مقدار اولیه برای وزن ها در یک شبکه عصبی برای جلوگیری از اختصاص وزن های کوچک توسط الگوریتم پس انتشار می باشد.
کاربرد (برخی از) RNN:
- تشخیص گفتار: هر کسی که با یک زبان خاص صحبت می کند، به زبان های مختلف ترجمه می شود. و همچنین صدا توسط دستگاه تشخیص داده می شود.
- ترجمه زبان: با استفاده از RNN، متن کاوی و تحلیل احساسات را می توان برای پردازش زبان طبیعی انجام داد (NLP).
- تشخیص تصویر و خصوصیات آن: RNN ها برای گرفتن تصویر با تجزیه و تحلیل فعالیت های حاضر استفاده می شود.
- پیش بینی سری های زمانی: هر مشکل پیش بینی سری زمانی، مانند پیش بینی قیمت سهام در یک ماه/ سال خاص را می توان با استفاده از RNN حل کرد.
اجرای RNN:
در این مبحث نحوه اجرای پیش بینی سری های زمانی را با استفاده از LSTM (حافظه کوتاه مدت/ بلند مدت) را بررسی خواهیم کرد.
اکنون چند کتابخانه اولیه را برای انجام توابع چارچوب داده وارد می کنیم.
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
در این قسمت من از مجموعه داده های قیمت سهام گوگل استفاده کرده ام. با استفاده از لینک زیر می توانید مجموعه داده را دانلود کنید.
https://www.kaggle.com/medharawat/google-stock-price
همچنین دو فایل به عنوان های google_stock_price_train.csv و google_stock_price_test.csv در آن مجموعه داده، ارائه شده است.
بنابراین ابتدا در اینجا قصد داریم فایل آموزشی را استفاده کنیم.
dataset_train = pd.read_csv(‘Google_Stock_Price_Train.csv’)
training_set = dataset_train.iloc[:, 1:2].values
در مرحله بعد، باید با استفاده از مقیاس بندی، داده ها را عادی سازی کنیم. داده های ما در یک قالب خاص مقیاس بندی می شوند. بنابراین ما به کتابخانه MinMaxScaler نیاز داریم.
from sklearn.preprocessing import MinMaxScaler
sc = MinMaxScaler(feature_range = (0, 1))
training_set_scaled = sc.fit_transform(training_set)
اکنون، ما یک ساختار داده با 60 گام زمانی و یک خروجی به عنوان آرایه (Array) x_train و y_train ایجاد می کنیم.
X_train = []
y_train = []
for i in range(60, 1258):
X_train.append(training_set_scaled[i-60:i, 0])
y_train.append(training_set_scaled[i, 0])
X_train, y_train = np.array(X_train), np.array(y_train)
در این مرحله ما تغییر شکل داده های x_train را انجام داده ایم.
X_train = np.reshape(X_train, (X_train.shape[0], X_train.shape[1], 1))
حال، برای ساخت مدل RNN و انجام عملیات آن به کتابخانه های زیر نیاز است. ما کتابخانه Keras و بسته هایش را وارد کرده ایم.
X_train = np.reshape(X_train, (X_train.shape[0], X_train.shape[1], 1))
بیایید RNN خود را مقدار دهی کنیم.
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
from keras.layers import Dropout
اکنون، اولین لایه LTSM و مقداری تنظیمDropout را اضافه کنید.
regressor.add(LSTM(units = 50, return_sequences = True, input_shape = (X_train.shape[1], 1)))
regressor.add(Dropout(0.2))
حال، لایه دوم LSTM و مقداری تنظیم Dropout را اضافه کنید.
regressor.add(LSTM(units = 50, return_sequences = True))
regressor.add(Dropout(0.2))
حالا، لایه سوم LTSM و مقداری تنظیم Dropout را اضافه کنید.
regressor.add(LSTM(units = 50, return_sequences = True))
regressor.add(Dropout(0.2))
اکنون، لایه چهارم LTSM و مقداری تنظیم Dropout را اضافه کنید.
regressor.add(LSTM(units = 50))
regressor.add(Dropout(0.2))
بیایید یک لایه خروجی اضافه کنیم.
regressor.add(Dense(units = 1))
ما از یک مجموعه داده آموزشی برای تناسب با مدل RNN استفاده می کنیم.
regressor.fit(X_train, y_train, epochs = 100, batch_size = 32)
Epoch 1/100
38/38 [==============================] – 4s 100ms/step – loss: 0.0419 0s – loss:
Epoch 2/100
38/38 [==============================] – 4s 104ms/step – loss: 0.0058
Epoch 3/100
38/38 [==============================] – 4s 99ms/step – loss: 0.0060
Epoch 4/100
38/38 [==============================] – 4s 98ms/step – loss: 0.0051
Epoch 5/100
38/38 [==============================] – 4s 100ms/step – loss: 0.0050
Epoch 6/100
38/38 [==============================] – 4s 99ms/step – loss: 0.0045
Epoch 7/100
38/38 [==============================] – 4s 101ms/step – loss: 0.0047
Epoch 8/100
38/38 [==============================] – 4s 100ms/step – loss: 0.0046
Epoch 9/100
38/38 [==============================] – 4s 101ms/step – loss: 0.0044
Epoch 10/100
38/38 [==============================] – 4s 103ms/step – loss: 0.0046
Epoch 11/100
38/38 [==============================] – 4s 103ms/step – loss: 0.0043
Epoch 12/100
38/38 [==============================] – 4s 101ms/step – loss: 0.0041
Epoch 13/100
38/38 [==============================] – 4s 100ms/step – loss: 0.0047
Epoch 14/100
38/38 [==============================] – 4s 100ms/step – loss: 0.0035
Epoch 15/100
38/38 [==============================] – 4s 100ms/step – loss: 0.0039
Epoch 16/100
38/38 [==============================] – 4s 100ms/step – loss: 0.0038
Epoch 17/100
38/38 [==============================] – 4s 100ms/step – loss: 0.0035
Epoch 18/100
38/38 [==============================] – 4s 100ms/step – loss: 0.0035
Epoch 19/100
38/38 [==============================] – 4s 100ms/step – loss: 0.0034
Epoch 20/100
38/38 [==============================] – 4s 100ms/step – loss: 0.0036
Epoch 21/100
38/38 [==============================] – 4s 102ms/step – loss: 0.0038
Epoch 22/100
38/38 [==============================] – 4s 100ms/step – loss: 0.0034
Epoch 23/100
38/38 [==============================] – 4s 101ms/step – loss: 0.0033
Epoch 24/100
38/38 [==============================] – 4s 101ms/step – loss: 0.0036
Epoch 25/100
38/38 [==============================] – 4s 102ms/step – loss: 0.0035
Epoch 26/100
38/38 [==============================] – 4s 102ms/step – loss: 0.0036
Epoch 27/100
38/38 [==============================] – 4s 102ms/step – loss: 0.0031
Epoch 28/100
38/38 [==============================] – 4s 106ms/step – loss: 0.0032
Epoch 29/100
38/38 [==============================] – 4s 103ms/step – loss: 0.0030
Epoch 30/100
38/38 [==============================] – 4s 102ms/step – loss: 0.0030
Epoch 31/100
38/38 [==============================] – 4s 102ms/step – loss: 0.0031
Epoch 32/100
38/38 [==============================] – 4s 101ms/step – loss: 0.0030 0s – lo
Epoch 33/100
38/38 [==============================] – 4s 103ms/step – loss: 0.0028
Epoch 34/100
38/38 [==============================] – 4s 102ms/step – loss: 0.0030
Epoch 35/100
38/38 [==============================] – 4s 101ms/step – loss: 0.0025
Epoch 36/100
38/38 [==============================] – 4s 101ms/step – loss: 0.0028
Epoch 37/100
38/38 [==============================] – 4s 101ms/step – loss: 0.0032
Epoch 38/100
38/38 [==============================] – 4s 102ms/step – loss: 0.0028
Epoch 39/100
38/38 [==============================] – 4s 102ms/step – loss: 0.0031
Epoch 40/100
38/38 [==============================] – 4s 102ms/step – loss: 0.0026
Epoch 41/100
38/38 [==============================] – 4s 102ms/step – loss: 0.0026
Epoch 42/100
38/38 [==============================] – 4s 106ms/step – loss: 0.0027
Epoch 43/100
38/38 [==============================] – 4s 105ms/step – loss: 0.0027
Epoch 44/100
38/38 [==============================] – 4s 104ms/step – loss: 0.0023
Epoch 45/100
38/38 [==============================] – 4s 106ms/step – loss: 0.0023
Epoch 46/100
38/38 [==============================] – 4s 103ms/step – loss: 0.0024
Epoch 47/100
38/38 [==============================] – 4s 103ms/step – loss: 0.0024 0s – loss: 0.002
Epoch 48/100
38/38 [==============================] – 4s 103ms/step – loss: 0.0025
Epoch 49/100
38/38 [==============================] – 4s 103ms/step – loss: 0.0025 0s – lo
Epoch 50/100
38/38 [==============================] – 4s 103ms/step – loss: 0.0023
Epoch 51/100
38/38 [==============================] – 4s 102ms/step – loss: 0.0023
Epoch 52/100
38/38 [==============================] – 4s 102ms/step – loss: 0.0024
Epoch 53/100
38/38 [==============================] – 4s 102ms/step – loss: 0.0022
Epoch 54/100
38/38 [==============================] – 4s 103ms/step – loss: 0.0023
Epoch 55/100
38/38 [==============================] – 4s 103ms/step – loss: 0.0022
Epoch 56/100
38/38 [==============================] – 4s 102ms/step – loss: 0.0025 0s – loss
Epoch 57/100
38/38 [==============================] – 4s 103ms/step – loss: 0.0023
Epoch 58/100
38/38 [==============================] – 4s 102ms/step – loss: 0.0022
Epoch 59/100
38/38 [==============================] – 4s 103ms/step – loss: 0.0022
Epoch 60/100
38/38 [==============================] – 4s 103ms/step – loss: 0.0021
Epoch 61/100
38/38 [==============================] – 4s 109ms/step – loss: 0.0021
Epoch 62/100
38/38 [==============================] – 4s 105ms/step – loss: 0.0020
Epoch 63/100
38/38 [==============================] – 4s 102ms/step – loss: 0.0020
Epoch 64/100
38/38 [==============================] – 4s 102ms/step – loss: 0.0022 0s – loss: 0.0 – ETA: 0s – loss: 0.002
Epoch 65/100
38/38 [==============================] – 4s 103ms/step – loss: 0.0024
Epoch 66/100
38/38 [==============================] – 4s 103ms/step – loss: 0.0021
Epoch 67/100
38/38 [==============================] – 4s 102ms/step – loss: 0.0020
Epoch 68/100
38/38 [==============================] – 4s 103ms/step – loss: 0.0019
Epoch 69/100
38/38 [==============================] – 4s 102ms/step – loss: 0.0020
Epoch 70/100
38/38 [==============================] – 4s 106ms/step – loss: 0.0022
Epoch 71/100
38/38 [==============================] – 4s 103ms/step – loss: 0.0020
Epoch 72/100
38/38 [==============================] – 4s 102ms/step – loss: 0.0018
Epoch 73/100
38/38 [==============================] – 4s 103ms/step – loss: 0.0020
Epoch 74/100
38/38 [==============================] – 4s 102ms/step – loss: 0.0016
Epoch 75/100
38/38 [==============================] – 4s 104ms/step – loss: 0.0018
Epoch 76/100
38/38 [==============================] – 4s 103ms/step – loss: 0.0018
Epoch 77/100
38/38 [==============================] – 4s 106ms/step – loss: 0.0019
Epoch 78/100
38/38 [==============================] – 4s 105ms/step – loss: 0.0017
Epoch 79/100
38/38 [==============================] – 4s 104ms/step – loss: 0.0019
Epoch 80/100
38/38 [==============================] – 4s 111ms/step – loss: 0.0018
Epoch 81/100
38/38 [==============================] – 5s 123ms/step – loss: 0.0017
Epoch 82/100
38/38 [==============================] – 4s 104ms/step – loss: 0.0017
Epoch 83/100
38/38 [==============================] – 4s 102ms/step – loss: 0.0017
Epoch 84/100
38/38 [==============================] – 4s 102ms/step – loss: 0.0015
Epoch 85/100
38/38 [==============================] – 4s 104ms/step – loss: 0.0015
Epoch 86/100
38/38 [==============================] – 4s 102ms/step – loss: 0.0015 0s – los
Epoch 87/100
38/38 [==============================] – 4s 101ms/step – loss: 0.0018
Epoch 88/100
38/38 [==============================] – 4s 102ms/step – loss: 0.0015
Epoch 89/100
38/38 [==============================] – 4s 102ms/step – loss: 0.0015 1s
Epoch 90/100
38/38 [==============================] – 4s 101ms/step – loss: 0.0017
Epoch 91/100
38/38 [==============================] – 4s 101ms/step – loss: 0.0017
Epoch 92/100
38/38 [==============================] – 4s 101ms/step – loss: 0.0017
Epoch 93/100
38/38 [==============================] – 4s 103ms/step – loss: 0.0014
Epoch 94/100
38/38 [==============================] – 4s 104ms/step – loss: 0.0017
Epoch 95/100
38/38 [==============================] – 4s 102ms/step – loss: 0.0016
Epoch 96/100
38/38 [==============================] – 4s 102ms/step – loss: 0.0013
Epoch 97/100
38/38 [==============================] – 4s 102ms/step – loss: 0.0014
Epoch 98/100
38/38 [==============================] – 4s 101ms/step – loss: 0.0015
Epoch 99/100
38/38 [==============================] – 4s 102ms/step – loss: 0.0014
Epoch 100/100
38/38 [==============================] – 4s 101ms/step – loss: 0.0014
اکنون، مرحله بعدی ما پیش بینی قیمت سهام و تجسم نتایج آنها است. در اینجا از قیمت واقعی سهام در سال 2017 با داده هایgoogle_stock_price.csv استفاده کرده ایم.
dataset_test = pd.read_csv(‘Google_Stock_Price_Test.csv’)
real_stock_price = dataset_test.iloc[:, 1:2].values
دریافت قیمت سهام پیش بینی شده در سال 2017
dataset_total = pd.concat((dataset_train[‘Open’], dataset_test[‘Open’]), axis = 0)
inputs = dataset_total[len(dataset_total) – len(dataset_test) – 60:].values
inputs = inputs.reshape(-1,1)
inputs = sc.transform(inputs)
X_test = []
for i in range(60, 80):
X_test.append(inputs[i-60:i, 0])
X_test = np.array(X_test)
X_test = np.reshape(X_test, (X_test.shape[0], X_test.shape[1], 1))
predicted_stock_price = regressor.predict(X_test)
predicted_stock_price = sc.inverse_transform(predicted_stock_price)
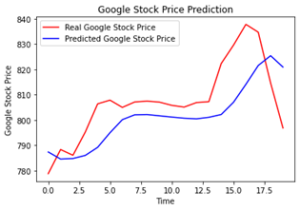
مرحله آخر این است که نتایج داده های خود را با استفاده از کتابخانه matplotlib تجسم کنیم.
plt.plot(real_stock_price, color = ‘red’, label = ‘Real Google Stock Price’)
plt.plot(predicted_stock_price, color = ‘blue’, label = ‘Predicted Google Stock Price’)
plt.title(‘Google Stock Price Prediction’)
plt.xlabel(‘Time’)
plt.ylabel(‘Google Stock Price’)
plt.legend()
plt.show()
تصویر نشان داده شده یک نمودار است که توسط کد بالا ترسیم شده است.
دیدگاهتان را بنویسید