انتخاب ویژگی ها و هم بستگی ها
تجزیه و تحلیل مؤلفه های اصلی با استفاده از پایتون (scikit-learn)
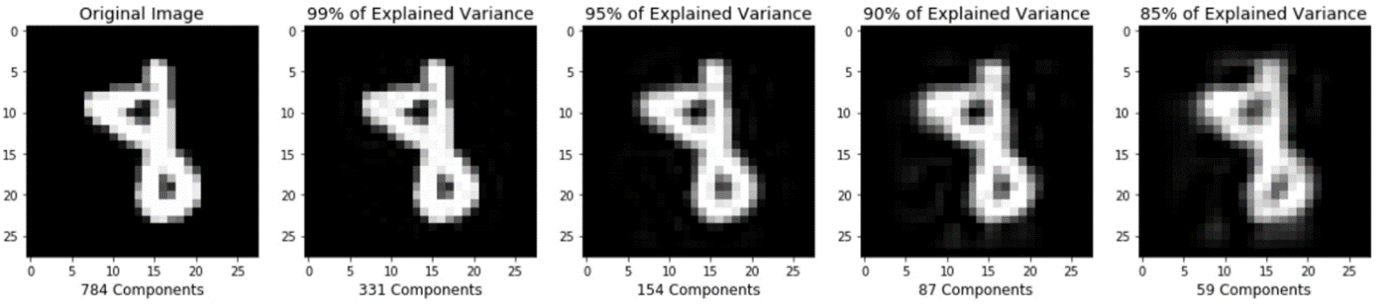
تصویر اصلی (سمت چپ) با مقادیر مختلف واریانس حفظ شده است.
آخرین آموزش من در مورد پس نمایی استدلالی (رگرسیون لجستیک) با استفاده از پایتون بود. یکی از چیز هایی که آموخته شد این بود که می توانید با تغییر الگوریتم بهینه سازی، برازش الگوریتم یادگیری ماشین را تسریع کنید. روش متداول تر برای افزایش سرعت الگوریتم یادگیری ماشین، استفاده از (PCA) است. اگر الگوریتم یادگیری شما به دلیل بعد ورودی بسیار زیاد کند است، استفاده از PCA برای سرعت بخشیدن به آن می تواند انتخاب معقولی باشد. این احتمالا رایج ترین کاربرد PCA است. یکی دیگر از کاربرد های رایج PCA برای تجسم داده ها است.
برای درک ارزش استفاده از PCA برای تجسم داده ها، قسمت اول این آموزش، به تجسم اولیه مجموعه داده “IRIS”پس از اعمال PCA می پردازد. بخش دوم از PCA برای سرعت بخشیدن به الگوریتم یادگیری ماشین (رگرسیون لوژیستیک) در مجموعه داده “MNIST” استفاده می کند.
بیایید شروع کنیم ! در صورت پیش آمدن مشکلی توصیه می شود این ویدیو را در یک صفحه جداگانه باز کنید.
PCA (تجزیه و تحلیل اجزای اصلی) برای تجسم داده
PCA به تجسم داده هایتان برای بسیاری از برنامه های یادگیری ماشینی، کمک میکند. تجسم داده های 2 یا 3 بعدی چندان چالش بر انگیز نیست. با این حال، حتی مجموعه داده “Iris” استفاده شده در این قسمت از آموزش، 4 بعدی است. شما می توانید از PCA برای کاهش داده های 4 بعدی به داده های 2 یا 3 بعدی استفاده کنید تا بتوانید داده ها را بهتر ترسیم و درک کنید.
بارگذاری مجموعه داده Iris
مجموعه داده Iris یکی از مجموعه داده های scikit-learn است که نیازی به دانلود هیچ فایلی از وب سایت خارجی ندارد. کد زیر مجموعه داده Iris را بار گذاری می کند.
import pandas as pd
url = “https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data“
# load dataset into Pandas DataFrame
df = pd.read_csv(url, names=[‘sepal length’,’sepal width’,’petal length’,’petal width’,’target’])
Original Pandas df (features + target)
استاندارد کردن داده ها
PCA بر اساس مقیاس انجام می شود، بنابراین قبل از اعمال PCA باید ویژگی های موجود در داده های خود را مقیاس بندی کنید. از “StandardScaler” برای کمک به استاندارد سازی ویژگی های مجموعه داده در مقیاس واحد (میانگین = 0 و واریانس = 1) استفاده کنید که لازمه بهینه سازی عملکرد بسیاری از الگوریتم های یادگیری ماشینی می باشد. اگر میخواهید تأثیر منفی عدم مقیاس گذاری داده هایتان را ببینید، scikit-learn توضیحی در مورد تأثیرات استاندارد نکردن داده ها دارد.
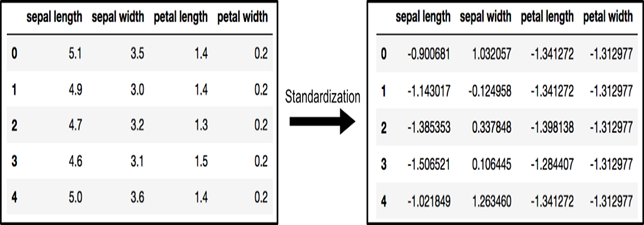
آرایه x (که توسط قالب داده پاندا ها تجسم شده است) قبل و بعد از استاندارد سازی
طرح ریزی یا تجسم PCA به دو بعدی (2D)
داده های اصلی دارای 4 ستون هستند (طول کاسبرگ (Sepal Length)، عرض کاسبرگ (Sepal Width)، طول گلبرگ (Petal Length) و عرض گلبرگ (Petal Width)). در این بخش، کد داده های اصلی را که 4 بعدی به 2 بعدی می باشد، نمایش می دهد. باید توجه داشته باشیم که معمولا پس از کاهش ابعاد، معنای خاصی به هر جزء اصلی اختصاص داده نمی شود. اجزای جدید فقط دو بعد اصلی تغییر هستند.
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
principalComponents = pca.fit_transform(x)
principalDf = pd.DataFrame(data = principalComponents
, columns = [‘principal component 1’, ‘principal component 2’])
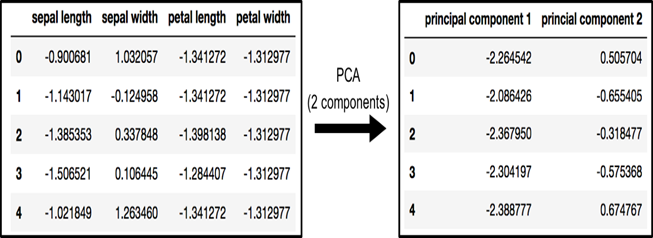
PCA و حفظ 2 جزء اصلی
finalDf = pd.concat([principalDf, df[[‘target’]]], axis = 1)
الحاق چارچوب داده در امتداد محور = 1 (DataFrame along axis = 1). Df نهایی (finalDf) چارچوب داده نهایی قبل از رسم داده است.
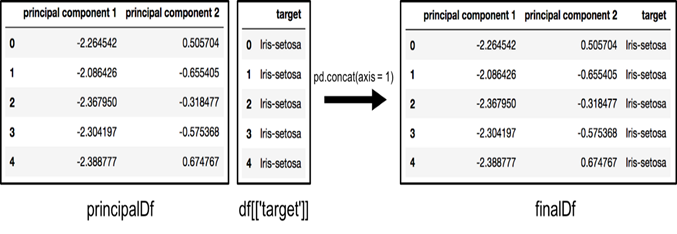
الحاق چارچوب های داده در امتداد ستون ها برای ساختن Df نهایی (finalDf) قبل از نمودار
تجسم طرح ریزی دو بعدی
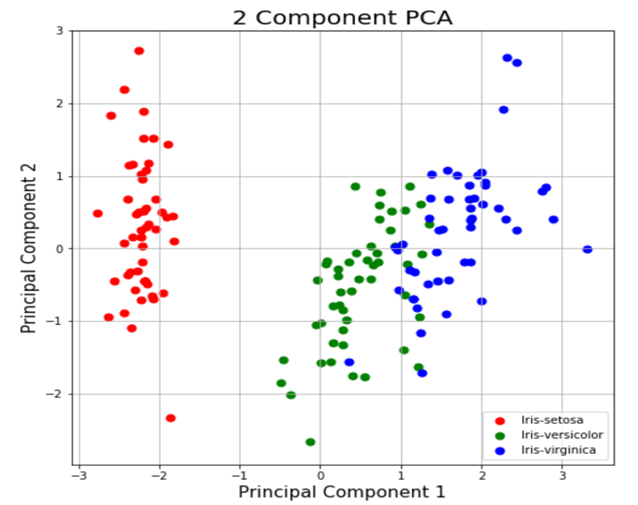
این بخش فقط داده های دو بعدی را ترسیم می کند. در نمودار زیر توجه کنید که طبقات به خوبی از یکدیگر جدا شده اند
fig = plt.figure(figsize = (8,8))
ax = fig.add_subplot(1,1,1)
ax.set_xlabel(‘Principal Component 1’, fontsize = 15)
ax.set_ylabel(‘Principal Component 2’, fontsize = 15)
ax.set_title(‘2 component PCA’, fontsize = 20)
targets = [‘Iris-setosa’, ‘Iris-versicolor’, ‘Iris-virginica’]
colors = [‘r’, ‘g’, ‘b’]
for target, color in zip(targets,colors):
indicesToKeep = finalDf[‘target’] == target
ax.scatter(finalDf.loc[indicesToKeep, ‘principal component 1’]
, finalDf.loc[indicesToKeep, ‘principal component 2’]
, c = color
, s = 50)
ax.legend(targets)
ax.grid()
نمودار PCA دو جزئی
واریانس توضیح داده شده
واریانس توضیح داده شده به شما می گوید که چه مقدار اطلاعات (واریانس) را می توان به هر یک از اجزای اصلی نسبت داد. این مهم است زیرا هنگامی که فضای 4 بعدی را به فضای 2 بعدی تبدیل می کنید، مقداری از واریانس (اطلاعات) را از دست می دهید. با استفاده از ویژگی “توضیح داده شده_واریانس_نسبت_“(explained_variance_ratio_)، می توانید ببینید که مؤلفه اصلی اول شامل 72.77 درصد از واریانس و مؤلفه اصلی دوم شامل 23.03 درصد از واریانس است. این دو مؤلفه با هم شامل 95.80 درصد اطلاعات هستند.
pca.explained_variance_ratio_
PCA برای افزایش سرعت الگوریتم های یادگیری ماشینی
در حالی که راه های دیگری برای سرعت بخشیدن به الگوریتم های یادگیری ماشینی وجود دارد، یکی از راه های کمتر شناخته شده استفاده از PCA است. برای این بخش، ما از مجموعه داده IRIS استفاده نمی کنیم زیرا این مجموعه داده فقط 150 ردیف و 4 ستون ویژگی دارد. پایگاه داده ارقام دست نویس MNIST مناسب تر است زیرا دارای 784 ستون ویژگی (784 بعد)، 60000 نمونه مجموعه آموزشی و 10000 نمونه مجموعه آزمایشی است.
داده ها را دانلود و بارگذاری کنید
همچنین می توانید یک پارامتر “data_home” به “fetch_mldata” اضافه کنید تا محلی که داده ها را دانلود می کنید تغییر دهید.
from sklearn.datasets import fetch_openml
mnist = fetch_openml(‘mnist_784’)
تصاویری که دانلود کردید در mnist.data موجود است و دارای شکل (70000، 784) می باشد؛ یعنی شامل 70000 تصویر و 784 بعد (784 ویژگی) است. برچسب ها (اعداد صحیح 0-9) در mnist.target موجود هستند. ویژگی ها 784 بعدی (28 x 28 تصاویر) هستند و برچسب ها اعدادی ساده از 0 تا 9 هستند.
جدا سازی داده ها به مجموعه های آموزشی و آزمایشی
به طور معمول جدا سازی آزمون آموزشی؛ 80 درصد آموزش و 20 درصد آزمون می باشد. در این حالت من 7/6 مقدار از داده ها را به عنوان آموزش و 7/1 از داده ها را به عنوان مجموعه آزمون انتخاب کردم.
from sklearn.model_selection import train_test_split
# test_size: what proportion of original data is used for test set
train_img, test_img, train_lbl, test_lbl = train_test_split( mnist.data, mnist.target, test_size=1/7.0, random_state=0)
استاندارد سازی داده ها
متن این پاراگراف تقریبا یک کپی دقیق از آن چه که قبلا نوشته شده است، می باشد. PCA بر اساس مقیاس انجام می شود، بنابراین قبل از اعمال PCA باید ویژگی های موجود در داده ها را مقیاس بندی کنید. شما می توانید داده ها را به مقیاس واحد تبدیل کنید (میانگین = 0 و واریانس = 1) که لازمه بهینه بسیاری عملکرد الگوریتم های یادگیری ماشینی است. StandardScaler به استاندارد کردن ویژگی های مجموعه داده کمک می کند. توجه داشته باشید که در مجموعه آموزشی قرار می گیرید و در مجموعه آموزشی و تست تبدیل می شوید. اگر میخواهید تأثیر منفی عدم مقیاس گذاری داده هایتان را ببینید، scikit-learn توضیحی در مورد تأثیرات استاندارد نکردن داده ها دارد.
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
# Fit on training set only.
scaler.fit(train_img)
# Apply transform to both the training set and the test set.
train_img = scaler.transform(train_img)
test_img = scaler.transform(test_img)
PCA را وارد و اعمال کنید
توجه داشته باشید که کد زیر دارای عدد 95, برای عدد هر پارامتر مؤلفه است. این بدان معنی است که scikit-learn حداقل تعداد مؤلفه های اصلی را انتخاب می کند به طوری که 95 درصد از واریانس حفظ شود.
from sklearn.decomposition import PCA
# Make an instance of the Model
pca = PCA(.95)
PCA را روی مجموعه آموزشی قرار دهید. توجه: PCA را فقط روی مجموعه آموزشی نصب میکنید.
pca.fit(train_img)
توجه: با استفاده از pca.n_components_ می توانید متوجه شوید که PCA چند مؤلفه را پس از برازش مدل انتخاب می کند. در این حالت 95 درصد واریانس به تعداد 330 مؤلفه اصلی می رسد.
نقشه برداری (تبدیل) را به هر دو مجموعه آموزش و مجموعه آزمون اعمال کنید.
train_img = pca.transform(train_img)
رگرسیون لجستیک را برای داده های تبدیل شده اعمال کنید
مرحله اول: مدلی را که می خواهید استفاده کنید را وارد کنید.
در sklearn، تمامی مدل های یادگیری ماشینی به صورت کلاس های پایتون پیاده سازی می شوند.
from sklearn.linear_model import LogisticRegression
مرحله دوم: یک نمونه از مدل بسازید.
# all parameters not specified are set to their defaults
# default solver is incredibly slow which is why it was changed to ‘lbfgs’
logisticRegr = LogisticRegression(solver = ‘lbfgs’)
مرحله سوم: آموزش مدل از روی داده ها، ذخیره اطلاعات بدست آمده از داده ها
مدل در حال یادگیری رابطه بین ارقام و برچسب ها می باشد.
logisticRegr.fit(train_img, train_lbl)
مرحله چهارم: برچسب های داده های جدید را پیش بینی کنید (تصاویر جدید)
از اطلاعاتی که مدل در طول فرآیند آموزش مدل آموخته، استفاده می کند.
کد زیر برای یک مشاهده (تحت نظر گرفتن)، پیش بینی می کند
# Predict for One Observation (image)
logisticRegr.predict(test_img[0].reshape(1,-1))
کد زیر مشاهدات متعدد را به طور همزمان پیش بینی می کند
# Predict for One Observation (image)
logisticRegr.predict(test_img[0:10])
اندازه گیری عملکرد مدل
در حالی که دقت همیشه بهترین معیار برای الگوریتم های یادگیری ماشینی نیست (دقت، یادآوری، امتیاز F1، منحنی ROC و غیره بهتر است)، اما در اینجا برای سادگی و سهولت استفاده می شود.
logisticRegr.score(test_img, test_lbl)
زمان بندی برازش رگرسیون لوژیستیک پس از PCA
هدف کلی این بخش از آموزش این بود که نشان دهد شما می توانید از PCA برای سرعت بخشیدن به برازش الگوریتم های یادگیری ماشینی استفاده کنید. جدول زیر نشان می دهد که پس از استفاده از PCA (با حفظ مقادیر مختلف واریانس در هر بار) چقدر طول کشید تا رگرسیون لوژثیستیک در مک بوک من مطابقت داده شود.
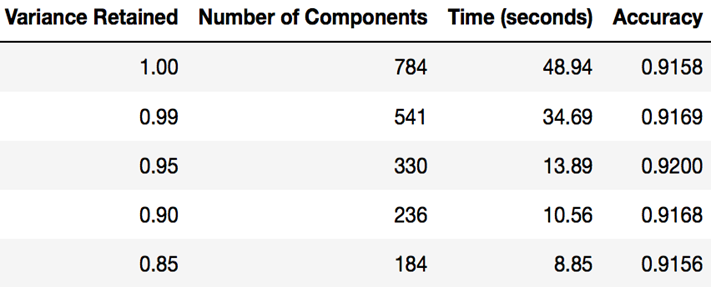
زمانی که برای برازش رگرسیون لوژیستیک پس از استفاده از PCA با کسر های مختلف واریانس حفظ شده طول کشید
بازسازی تصویر از نمایش فشرده
بخش های قبلی آموزش استفاده از PCA را برای فشرده سازی داده ها با ابعاد زیاد تر به داده هایی با ابعاد کم تر نشان داده اند. به طور خلاصه می توان اشاره کرد که PCA همچنین میتواند نمایش فشرده داده ها (داده ها با ابعاد کم تر) را به تقریبی از داده هایی با ابعاد زیاد اصلی برگرداند. اگر به کدی که تصویر زیر را تولید می کند علاقه مند هستید، github نویسنده این متن را بررسی کنید./
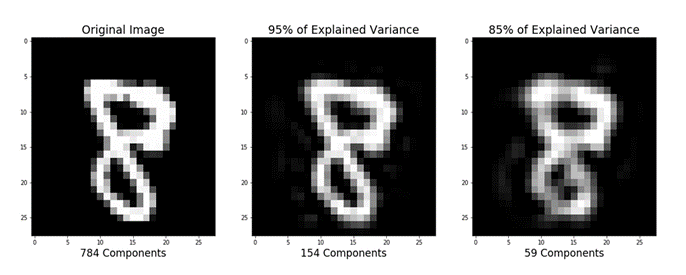
تصویر اصلی (سمت چپ) و تقریب (راست) داده های اصلی پس از PCA
دیدگاهتان را بنویسید