داده های نامتوازن 1
مرور کلی
- آشنایی با طبقه بندی نا متوازن
- درک تکنیک های مختلف برای مواجه با طبقه بندی نا متوازن مانند:
- کم نمونه گیری تصادفی (Random under-sampling)
- بیش نمونه گیری تصادفی (Random over-sampling)
- NearMiss
- در اینجا می توانید پیاده سازی کد موجود در منبع GitHub من را بررسی کنید
معرفی
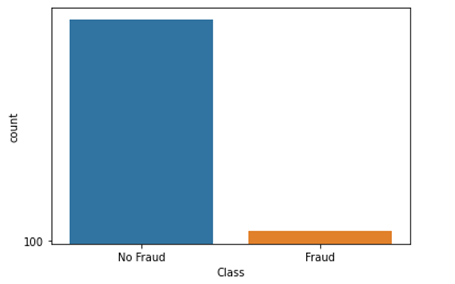
وقتی نظارت در یک طبقه بالاتر از نظارت در طبقه های دیگر باشد، عدم تعادل طبقه ای وجود دارد. مثال: شناسایی تراکنش های جعلی کارت اعتباری. همان طور که در نمودار زیر مشاهده می کنید، در مقایسه تراکنش جعلی با تراکنش غیر جعلی، جعلی در حدود 400 می باشد در حالی که غیر جعلی حدود 90000 است.
طبقه بندی نا متوازن یک مشکل رایج در یادگیری ماشینی، به ویژه در مسائل طبقه بندی است. طبقه بندی داده های نا متوازن می تواند دقت مدل ما را تا حد زیادی مختل کند.
طبقه بندی نا متوازن در بسیاری از دامنه ها ظاهر می شود، از جمله:
- تشخیص جعل
- فیلتر کردن هرزنامه
- غربالگری بیماری
- ریزش اشتراک SaaS
- تبلیغات کلیکی
مشکل طبقه بندی نا متوازن
اکثر الگوریتم های یادگیری ماشینی زمانی بهترین کارآیی را دارند که تعداد نمونه ها در هر طبقه تقریبا برابر باشد. این به این دلیل است که اکثر الگوریتم ها برای به حداکثر رساندن دقت و کاهش خطا طراحی شده اند.
با این حال، اگر مجموعه داده ها در عدم تعادل باشد، در چنین مواردی، فقط با پیش بینی طبقه اکثریت، صحت بسیار بالایی به دست می آورید، اما نمی توانید طبقه اقلیت را به دست آورید، که اغلب نقطه ایجاد مدل در وهله اول است.
مثال تشخیص جعل کارت اعتباری
فرض کنید مجموعه داده ای از شرکت های کارت اعتباری داریم که باید بفهمیم که آیا تراکنش کارت اعتباری جعلی بوده است یا خیر.
اما نکته اینجاست… تراکنش جعلی نسبتا نادر است، تنها 6 درصد از تراکنش جعلی است.
|
def transaction(transaction_data): return ‘No fradulent transaction’
|
حالا، قبل از شروع، آیا می بینید که چگونه ممکن است مشکل از بین برود؟ تصور کنید اصلا زحمت آموزش یک مدل را نمی کشید. در عوض، فقط یک خط کد می نویسید که همیشه « تراکنش غیر جعلی (‘no fraudulent transaction’) » را پیش بینی می کند.
حدس بزنید چه اتفاقی خواهد افتاد؟ “راه حل” شما 94% دقت خواهد داشت!
متأسفانه، این دقت گمراه کننده است.
- در تمام آن تراکنش های غیر جعلی، شما 100% دقت خواهید داشت.
- در آن تراکنش هایی که جعلی هستند، دقت 0% خواهید داشت.
- دقت کلی شما فقط به این دلیل بالاست که بیشترین تراکنش، تراکنش جعلی نیست (نه به این دلیل که مدل شما خوب است).
این به وضوح یک مشکل است زیرا بسیاری از الگوریتم های یادگیری ماشینی برای به حداکثر رساندن دقت کلی طراحی شده اند. در این مقاله، تکنیک های مختلفی برای مدیریت داده های نا متعادل خواهیم دید.
داده ها
ما از یک مجموعه داده شناسایی تقلب در کارت اعتباری برای این مقاله استفاده می کنیم که می توانید مجموعه داده را از اینجا پیدا کنید. پس از بارگذاری داده ها، پنج ردیف اول مجموعه داده را نمایش دهید.
|
# check the target variable that is fraudulet and not fradulent transactiondata[‘Class’].value_counts()# 0 -> non fraudulent # 1 -> fraudulent
|
|
# visualize the target variable g = sns.countplot(data[‘Class’]) g.set_xticklabels([‘Not Fraud’,’Fraud’]) plt.show() # visualize the target variable g = sns.countplot(data[‘Class’]) g.set_xticklabels([‘Not Fraud’,’Fraud’]) plt.show() |
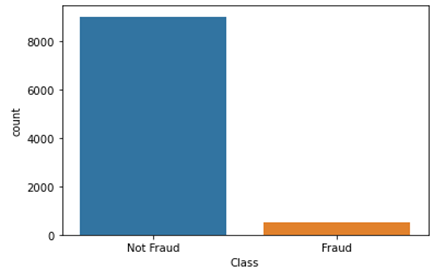
شما به وضوح می بینید که تفاوت زیادی بین مجموعه داده های 9000 تراکنش غیر جعلی و 492 تراکنش جعلی وجود دارد.
تله متریک یا تله معیار
یکی از مسائل مهمی که کاربران توسعه دهنده جدید هنگام برخورد با مجموعه داده های نا متوازن با آن مواجه می شوند، به معیار های مورد استفاده برای ارزیابی مدل آن ها مربوط می شود. استفاده از معیار های ساده تر مانند امتیاز دقت می تواند گمراه کننده باشد. در یک مجموعه داده با طبقه های بسیار نا متوازن، طبقه بندی کننده همیشه رایج ترین طبقه را بدون انجام هیچ گونه تحلیلی از ویژگی ها «پیشبینی» می کند و نرخ دقت بالایی دارد، اما بدیهی است که درست نیست. بیایید این آزمایش را با استفاده از XGBClassifier ساده و بدون مهندسی ویژگی انجام دهیم:
|
# import linrary from xgboost import XGBClassifier xgb_model = XGBClassifier().fit(x_train, y_train) # predict xgb_y_predict = xgb_model.predict(x_test) # accuracy score xgb_score = accuracy_score(xgb_y_predict, y_test) print(‘Accuracy score is:’, xbg_score)OUTPUT Accuracy score is: 0.992
|
ما میتوانیم دقت 99% را ببینیم، دقت بسیار بالایی دریافت میکنیم زیرا بیشتر طبقه اکثریت را پیش بینی می کند که 0 است (غیر جعلی).
تکنیک نمونه گیری مجدد
روشی که به طور گسترده برای برخورد با مجموعه داده های بسیار نا متوازن پذیرفته شده است، نمونه گیری مجدد نامیده می شود. این روش شامل حذف نمونه ها از کلاس اکثریت (کم نمونه گیری) و یا افزودن نمونه های بیشتر از کلاس اقلیت (بیش نمونه گیری) است.
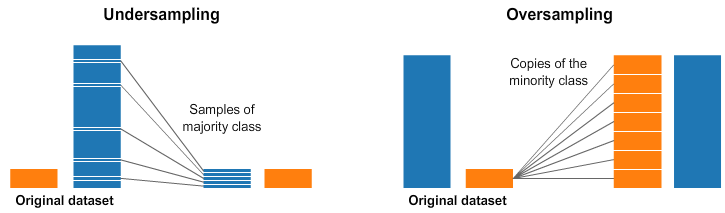
با وجود مزیت طبقه های متوازن کننده، این تکنیک ها نقاط ضعف خود را نیز دارند (هیچ چیز بدون هزینه نیست.).
ساده ترین پیاده سازی بیش نمونه گیری، تکرار رکورد های تصادفی از طبقه اقلیت است که می تواند باعث نمونه گیری بیش از حد شود.
در کم نمونه گیری، ساده ترین تکنیک شامل حذف رکورد های تصادفی از طبقه اکثریت است که می تواند باعث از دست رفتن اطلاعات شود.
بیایید این را با مثال تشخیص جعل کارت اعتباری پیاده سازی کنیم.
|
# class count class_count_0, class_count_1 = data[‘Class’].value_counts() # Separate class class_0 = data[data[‘Class’] == 0] class_1 = data[data[‘Class’] == 1]# print the shape of the class print(‘class 0:’, class_0.shape) (print(‘class 1:’, class_1.shape
|
با جدا کردن طبقه ای که 0 و طبقه ای که 1 خواهد بود شروع می کنیم.
- کم نمونه گیری تصادفی
کم نمونه گیری را می توان به عنوان حذف برخی از مشاهدات طبقه اکثریت تعریف کرد. این کار تا زمانی انجام می شود که طبقه اکثریت و اقلیت متعادل شود.
|
class_0_under = class_0.sample(class_count_1) test_under = pd.concat([class_0_under, class_1], axis=0) print(“total class of 1 and0:”,test_under[‘Class’].value_counts())# plot the count after under-sampeling test_under[‘Class’].value_counts().plot(kind=’bar’, title=’count (target)’)
|
وقتی تعداد زیادی داده در اختیار دارید – به میلیون ها ردیف فکر کنید، کم نمونه گیری می تواند انتخاب خوبی باشد. اما یک اشکال کم نمونه گیری این است که ما در حال حذف اطلاعاتی هستیم که ممکن است ارزشمند باشند.
- بیش نمونه گیری تصادفی
بیش نمونه گیری را می توان به عنوان افزودن کپی های بیشتر به طبقه اقلیت تعریف کرد. بیش نمونه گیری برای زمانی که سر و کار با حجم زیادی از داده ها ندارید، می تواند انتخاب خوبی باشد.
|
class_1_over = class_1.sample(class_count_0, replace=True) test_over = pd.concat([class_1_over, class_0], axis=0) print(“total class of 1 and 0:”,test_under[‘Class’].value_counts())# plot the count after under-sampeling test_over[‘Class’].value_counts().plot(kind=’bar’, title=’count (target)’)
|
نکته ای که باید در هنگام کم نمونه گیری در نظر گرفت این است که می تواند باعث تطبیق بیش از حد و تعمیم ضعیف به مجموعه آزمایشی شما شود.
تعادل داده ها را با ماژول پایتون یادگیری-نا متعادل برقرار کنید
تعدادی از تکنیک های پیچیده تر نمونه گیری مجدد در ادبیات علمی پیشنهاد شده اند. به عنوان مثال، می توانیم رکورد های طبقه اکثریت را خوشه بندی کنیم، و با حذف رکورد ها از هر خوشه، کم نمونه گیری را انجام دهیم، بنابراین به دنبال حفظ اطلاعات هستیم. در بیش نمونه گیری، به جای ایجاد کپی های دقیق از رکورد های طبقه اقلیت، می توانیم تغییرات کوچکی را در آن نسخه ها وارد کنیم و نمونه های مصنوعی متنوع تری ایجاد کنیم.
|
import imblearn
|
بیایید برخی از این تکنیک های نمونه گیری مجدد را با استفاده از کتابخانه یادگیری-نامتعادل Python اعمال کنیم. این کتابخانه با scikit-learn سازگار است و بخشی از پروژه های scikit-learn-contrib می باشد.
3 . کم نمونه گیری تصادفی با استفاده از imblearn
RandomUnderSampler یک راه سریع و آسان برای متعادل کردن داده ها با انتخاب تصادفی زیر مجموعه ای از داده ها برای طبقه های هدف است.
|
# import library from imblearn.under_sampling import RandomUnderSampler rus = RandomUnderSampler(random_state=42, replacement=True)# fit predictor and target variable x_rus, y_rus = rus.fit_resample(x, y) print(‘original dataset shape:’, Counter(y)) print(‘Resample dataset shape’, Counter(y_rus))
|
با انتخاب تصادفی نمونه هایی با یا بدون جایگزین، از طبقه(های) اکثریت نمونه گیری حداقل کنید.
- بیش نمونه گیری تصادفی با استفاده از imblearn
یکی از راه های مبارزه با داده های نا متوازن، تولید نمونه های جدید در طبقه های اقلیت است. بی تکلف ترین استراتژی، تولید نمونه های جدید با استفاده از نمونه گیری تصادفی با جایگزینی نمونه های موجود در حال حاضر است. RandomOverSampler چنین طرحی را ارائه می دهد.
|
# import library from imblearn.over_sampling import RandomOverSampler ros = RandomOverSampler(random_state=42) # fit predictor and target variablex_ros, y_ros = ros.fit_resample(x, y) print(‘Original dataset shape’, Counter(y)) print(‘Resample dataset shape’, Counter(y_ros))
|

- کم نمونه گیری: پیوند های Tomek
پیوند های Tomek جفت هایی از نمونه های بسیار نزدیک اما از کلاس های متضاد هستند. حذف نمونه های طبقه اکثریت هر جفت، فضای بین دو طبقه را افزایش می دهد و فرآیند طبقه بندی را تسهیل می کند. پیوند Tomek در صورتی وجود دارد که دو نمونه نزدیک ترین همسایه یک دیگر باشند.
|
# import library from imblearn.under_sampling import TomekLinks tl = RandomOverSampler(sampling_strategy=’majority’) # fit predictor and target variable x_tl, y_tl = ros.fit_resample(x, y) print(‘Original dataset shape’, Counter(y)) print(‘Resample dataset shape’, Counter(y_ros))
|
در کد زیر، از ‘ratio=’majority برای نمونه برداری مجدد از طبقه اکثریت استفاده میکنیم.
import library
from imblearn.under_sampling import TomekLinks
tl = RandomOverSampler(sampling_strategy=’majority’)
# fit predictor and target variable
x_tl, y_tl = ros.fit_resample(x, y)
print(‘Original dataset shape’, Counter(y))
print(‘Resample dataset shape’, Counter(y_ros))

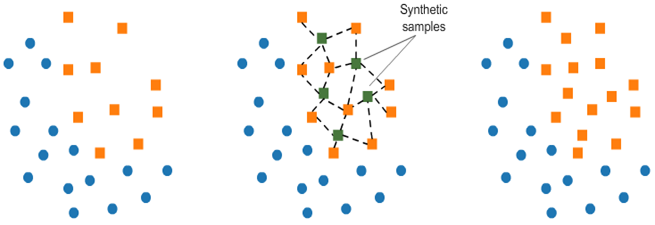
- روش بیش نمونه گیری اقلیت مصنوعی (SMOTE)
این تکنیک داده های مصنوعی را برای طبقه اقلیت تولید می کند.
SMOTE (روش بیش نمونه گیری اقلیت مصنوعی) با انتخاب تصادفی یک نقطه از طبقه اقلیت و محاسبه k-nearest neighbors برای این نقطه کار میکند. نقاط مصنوعی بین نقطه انتخاب شده و همسایگان آن اضافه می شوند.
الگوریتم SMOTE در 4 مرحله ساده کار می کند:
- یک طبقه اقلیت را به عنوان بردار ورودی انتخاب کنید
- k nearest neighbors آن را پیدا کنید (k_neighbors به عنوان آرگومان در تابع ()SMOTEمشخص شده است)
- یکی از این همسایگان را انتخاب کنید و یک نقطه مصنوعی را در هر نقطه از خطی که به نقطه مورد نظر و همسایه انتخابی آن می پیوندد، قرار دهید.
- مراحل را تکرار کنید تا داده ها متعادل شوند
|
# import library from imblearn.over_sampling import SMOTE smote = SMOTE() # fit predictor and target variable x_smote, y_smote = smote.fit_resample(x, y) print(‘Original dataset shape’, Counter(y)) print(‘Resample dataset shape’, Counter(y_ros))
|
- NearMiss
NearMiss یک تکنیک کم نمونه گیری است. به جای نمونه گیری مجدد از طبقه اقلیت، با استفاده از فاصله، این کار باعث می شود که طبقه اکثریت با طبقه اقلیت برابر شود.
|
from imblearn.under_sampling import NearMiss nm = NearMiss() x_nm, y_nm = nm.fit_resample(x, y) print(‘Original dataset shape:’, Counter(y)) print(‘Resample dataset shape:’, Counter(y_nm))
|
- معیار یا متریک عملکرد را تغییر دهید
دقت بهترین معیار برای ارزیابی مجموعه داده های نامتوازن نمی باشد زیرا ممکن است گمراه کننده باشد.
معیار هایی که می توانند بینش بهتری ارائه دهند عبارتند از:
- ماتریس سردرگمی (Confusion Matrix): جدولی که پیش بینی های صحیح و انواع پیش بینی های نادرست را نشان می دهد.
- دقت (Precision): تعداد مثبت های واقعی تقسیم بر تمام پیش بینی های مثبت. به دقت، ارزش پیش بینی مثبت نیز میگویند. این معیاری برای دقت طبقه بندی کننده است. دقت پایین نشان دهنده تعداد بالای مثبت کاذب است.
- فراخوانی (Precision): تعداد مثبت های واقعی تقسیم بر تعداد مقادیر مثبت در داده های آزمایش. به این فراخوان حساسیت یا نرخ مثبت واقعی نیز گفته می شود. این معیار، معیار کامل بودن طبقه بندی کننده است. فراخوان کم نشان دهنده تعداد بالای منفی کاذب است.
- F1: امتیاز (score): میانگین وزنی دقت و فراخوانی.
- ناحیه زیر منحنی (AUROC) ROC: AUROC احتمال تمایز مدل شما از مشاهدات از دو طبقه را نشان می دهد.
به عبارت دیگر، اگر به طور تصادفی یک مشاهده را از هر طبقه انتخاب کنید، احتمال اینکه مدل شما بتواند آنها را به درستی «رتبه بندی» کند چقدر است؟
- الگوریتم های مجازات (آموزش حساس به هزینه)
تاکتیک بعدی استفاده از الگوریتم های یادگیری جریمه شده است که هزینه اشتباهات طبقه بندی را در طبقه اقلیت افزایش می دهد. یک الگوریتم محبوب برای این تکنیک Penalized-SVM است.
در طول آموزش، میتوانیم از آرگومان’class_weight=’balanced برای مجازات اشتباهات در طبقه اقلیت توسط یک مقدار متناسب با نحوه کم نشان دادن آن استفاده کنیم.
اگر بخواهیم تخمین های احتمالی را برای الگوریتم های SVM فعال کنیم، باید آرگومان probability=True را نیز وارد کنیم. بیایید مدلی را با استفاده از
Penalized-SVM در مجموعه داده اصلی نا متعادل آموزش دهیم:
|
# load library from sklearn.svm import SVC # we can add class_weight=’balanced’ to add panalize mistake svc_model = SVC(class_weight=’balanced’, probability=True) svc_model.fit(x_train, y_train) svc_predict = svc_model.predict(x_test)# check performance print(‘ROCAUC score:’,roc_auc_score(y_test, svc_predict)) print(‘Accuracy score:’,accuracy_score(y_test, svc_predict)) print(‘F1 score:’,f1_score(y_test, svc_predict))
|
- 10. الگوریتم را تغییر دهید
در حالی که در هر مشکل یادگیری ماشینی، امتحان الگوریتم های مختلف یک قانون خوب است، اما میتواند به خصوص با مجموعه داده های نا متعادل مفید باشد.
درخت های تصمیم گیری اغلب روی داده های نا متعادل عملکرد خوبی دارند. در یادگیری ماشینی مدرن، مجموعه های درختی (جنگل های تصادفی، درختان تقویت شده با گرادیان، و غیره) تقریبا همیشه از درخت های تصمیمگیری منفرد بهتر عمل میکنند، بنابراین ما مستقیما به آن ها میپردازیم:
الگوریتم پایه درختی با یادگیری سلسله مراتبی از سوالات if/else کار می کند. این می تواند هر دو طبقه را مجبور کند که آدرس دهی شوند.
|
# load library from sklearn.ensemble import RandomForestClassifier rfc = RandomForestClassifier() # fit the predictor and target rfc.fit(x_train, y_train) # predict rfc_predict = rfc.predict(x_test)# check performance print(‘ROCAUC score:’,roc_auc_score(y_test, rfc_predict)) print(‘Accuracy score:’,accuracy_score(y_test, rfc_predict)) print(‘F1 score:’,f1_score(y_test, rfc_predict))
|
مزایا و معایب کم نمونه گیری
مزایا
- این می تواند با کاهش تعداد نمونه های داده های آموزشی در زمانی که مجموعه داده های آموزشی بسیار زیاد است، به بالا بردن زمان اجرا و بهبود مشکلات ذخیره سازی کمک کند.
معایب
- می تواند اطلاعات مفید بالقوه را که برای ساخت قوانین طبقه بندیکننده مهم باشد، کنار بگذارد.
- نمونه انتخاب شده با نمونه گیری تصادفی زیر ممکن است یک نمونه مغرضانه باشد. و نمایش دقیقی از جمعیت نخواهد بود. در نتیجه، منجر به نتایج نادرست با مجموعه داده های آزمایش واقعی می شود.
مزایا و معایب بیش نمونه گیری
مزایا
- برخلاف کم نمونه گیری، این روش منجر به از دست دادن اطلاعات نمی شود.
- تحت نمونه گیری عملکرد بهتری دارد
معایب
- از آنجایی که رویداد های طبقه اقلیت را تکرار می کند، احتمال برازش بیش از حد را افزایش می دهد.
از اینجا می توانید اجرای کد موجود در مخزن GitHub من را بررسی کنید. منابع
- https://elitedatascience.com/imbalanced-classes
- https://towardsdatascience.com/methods-for-dealing-with-imbalanced-data-5b761be45a18
نتیجه گیری
به طور خلاصه، در این مقاله، ما تکنیک های مختلفی را برای مدیریت عدم توازن طبقه در یک مجموعه داده دیده ایم. در واقع روش های زیادی وجود دارد که می توان هنگام برخورد با داده های نا متوازن امتحان کرد. امید است که این مقاله مفید بوده باشد./
دیدگاهتان را بنویسید