یادگیری نظارت شده 4

سلام! در این مقاله به اصول اولیه ایجاد مدل طبقه بندی خود با پایتون می پردازم. من سعی خواهم کرد مراحل آماده سازی داده ها، آموزش مدل شما، بهینه سازی مدل و نحوه ذخیره آن را برای استفاده بعدی به شما توضیح دهم و به شما نشان دهم. این مقاله دومین قسمت از مجموعه کوچکی است که من روی آن کار کرده ام، اگر مقاله قبلی من در مورد “رگرسیون خطی چندگانه با استفاده از پایتون” را نخوانده اید، حتما آن را بررسی کنید.
می توانید با استفاده از نوت بوک اینجا را دنبال کنید، موفق باشید و لذت ببرید!
مقدمه
در یادگیری ماشینی، طبقه بندی، مشکل شناسایی این است که مشاهدات جدید به کدام یک از مجموعه ای از دسته ها (جمعیت های فرعی) تعلق دارد، بر اساس یک مجموعه آموزشی از داده های حاوی مشاهدات (یا نمونه هایی) که عضویت آنها در دسته مشخص است. چند مثال از مشکلات طبقه بندی عبارتند از: (الف) تصمیم گیری در مورد اینکه ایمیل دریافتی هرزنامه است یا یک ایمیل اصلی. ب) تعیین تشخیص بیمار بر اساس ویژگی های مشاهده شده بیمار (سن، فشار خون، وجود یا عدم وجود علائم خاص و غیره)
در این مقاله از مجموعه داده های بازاریابی بانکی از Kaggle برای ساخت مدلی برای پیش بینی اینکه آیا کسی بسته به برخی ویژگی ها قرار است سپرده گذاری کند یا خیر، استفاده می کنیم. ما سعی خواهیم کرد 4 مدل مختلف را با استفاده از الگوریتم های مختلف درخت تصمیم گیری، جنکل تصمیم گیری، بیز ساده لوح و k-نزدیک ترین همسایه بسازیم. پس از ساخت هر مدل، آنها را ارزیابی کرده و با هم مقایسه می کنیم که کدام مدل برای مورد ما بهترین است. سپس با استفاده از GridSearch سعی می کنیم مدل خود را با تنظیم فرا پارامتر ها بهینه سازی کنیم. در نهایت، نتیجه پیش بینی را از مجموعه داده های خود ذخیره می کنیم و سپس مدل خود را برای قابلیت استفاده مجدد ذخیره می کنیم.
برای شروع، چند کتابخانه اصلی مانند Pandas و NumPy را بارگذاری می کنیم و سپس برخی از آن کتابخانه ها را پیکربندی می کنیم.
1 # Import libraries
2 ## Basic libs
3 import pandas as pd
4 import numpy as np
5 import warnings
6 ## Data Visualization
7 import seaborn as sns
8 import matplotlib.pyplot as plt
9
10 # Configure libraries
11 warnings.filterwarnings(‘ignore’)
12 plt.rcParams[‘figure.figsize’] = (10, 10)
13 plt.style.use(‘seaborn’)
پیش پردازش داده ها
قبل از اینکه بتوانیم اولین مدل خود را ایجاد کنیم، ابتدا باید بارگذاری و پیش پردازش کنیم. این مرحله تضمین می کند که مدل ما داده های خوبی برای یادگیری دریافت می کند، همان طور که می گویند «مدل به اندازه داده هایش خوب است». پیش پردازش داده ها به چند مرحله تقسیم می شود که در زیر توضیح داده شده است.
بارگیری داده ها
در این مرحله اول، مجموعه داده های خود را که در GitHub من آپلود شده است را برای فرآیند آسان تر بارگذاری می کنیم. از اسناد مجموعه داده ای که در اینجا می توانید پیدا کنید، می توانیم لیست ستون هایی را که در داده های خود داریم را در زیر مشاهده کنیم:
متغیرهای ورودی:
- سن (عددی)
- شغل: نوع شغل (مقوله: «مدیر»، «یقه-آبی»، «کارآفرین»، «خدمت کار خانه»، «مدیریت»، «بازنشسته»، «خوداشتغالی»، «خدمات»، «دانشجو»، «تکنسین» ، “بیکار” ، “ناشناس”)
- تأهل: وضعیت تأهل (مقوله: «طلاق»، «متاهل»، «مجرد»، «ناشناس»؛ توجه: «طلاق» به معنای مطلقه یا بیوه است)
- تحصیلات (مقوله: «پایه. 4 سال»، «پایه. 6 سال»، «پایه. 9 سال»، «دبیرستان»، «بی سواد»، « دوره .حرفه ای»، « مدرک تحصیلی.دانشگاه »، «نامعلوم»)
- پیش فرض: آیا اعتبار به طور پیش فرض وجود دارد؟ (مقوله: «نه»، «بله»، «نا شناس»)
- مسکن: وام مسکن دارد؟ (مقوله: «نه»، «بله»، «ناشناس»)
- وام: وام شخصی دارد؟ (مقوله: «نه»، «بله»، «ناشناس»)
- تماس: نوع ارتباط تماس (دسته بندی: “تلفنی”، “تلفن”)
- ماه: آخرین ماه تماس سال (دسته بندی: “ژانویه”، “فوریه”، “مارس”، …، “نوامبر”، “دسامبر”)
- روز هفته: آخرین روز تماس هفته (دسته بندی: “دوشنبه”، “سه شنبه”، “چهارشنبه”، “پنجشنبه، “جمعه”)
- مدت زمان: آخرین مدت تماس، بر حسب ثانیه (عددی). نکته مهم: این ویژگی به شدت بر هدف خروجی تأثیر می گذارد (به عنوان مثال، اگر مدت زمان=0، سپس y = ‘no’). با این حال، مدت زمان قبل از انجام تماس مشخص نیست. همچنین پس از پایان تماس y مشخص است. بنابراین، این ورودی فقط باید برای اهداف معیار گنجانده شود و اگر قصد داشتن یک مدل پیش بینی واقعی باشد، باید کنار گذاشته شود.
- کمپین: تعداد مخاطبین انجام شده در طول این کمپین و برای این مشتری (عددی، شامل آخرین تماس)
- pdays: تعداد روز هایی که پس از آخرین تماس با مشتری از کمپین قبلی گذشته است (عددی؛ 999 به این معنی است که مشتری قبلا با او تماس گرفته نشده است)
- قبلی: تعداد مخاطبین انجام شده قبل از این کمپین و برای این مشتری (عددی)
- poutcome : نتیجه کمپین بازاریابی قبلی (مقوله: “شکست”، “موفقیت”)
متغیر خروجی (هدف مورد نظر):
- y: آیا مشتری سپرده مدت دار را ثبت کرده است؟ (دودویی (باینری): “بله”، “نه”)
با توجه به مستندات مجموعه داده، ما باید ستون “مدت” را حذف کنیم زیرا در حالت واقعی مدت زمان تنها پس از مشخص شدن ستون برچسب مشخص می شود. این مشکل را می توان «نشت داده یا data leakage» در نظر گرفت که در آن پیش بینی کننده ها شامل داده هایی می شوند که در زمان پیش بینی شما در دسترس نخواهند بود.
| 1 # Load dataset | |
| 2 df_bank = pd.read_csv(‘https://raw.githubusercontent.com/rafiag/DTI2020/main/data/bank.csv’) | |
| 3 | |
| 4 # Drop ‘duration’ column | |
| 5 df_bank = df_bank.drop(‘duration’, axis=1) | |
| 6 | |
| 7 # print(df_bank.info()) | |
| 8 print(‘Shape of dataframe:’, df_bank.shape) | |
| 9 df_bank.head() |
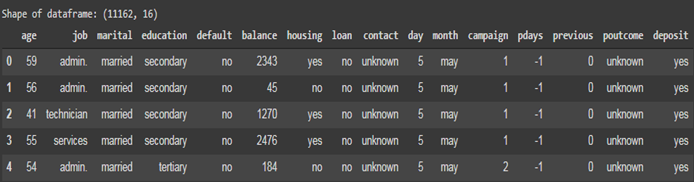
نمونه ای از داده هایی که روی آن کار خواهیم کرد.
توزیع کلاس
نکته مهم دیگری که باید قبل از وارد کردن داده ها به مدل مطمئن شویم، توزیع کلاسی داده ها است. در مورد ما که کلاس مورد انتظار به دو نتیجه “بله” و “خیر” تقسیم می شود، توزیع کلاس 50:50 می تواند توزیع ایده آل در نظر گرفته شود.
1 df_bank[‘deposit’].value_counts()
no 5873
yes 5289
Name: deposit, dtype: int64
همان طور که می بینیم توزیع کلاس ما کم و بیش مشابه است، توزیع دقیقا 50:50 نیست اما هنوز به اندازه کافی خوب است.
ارزش از دست رفته
آخرین چیزی که قبل از ادامه باید بررسی شود مقادیر از دست رفته است. در برخی موارد ممکن است داده های ما در برخی از ستون ها دارای مقادیر گم شده باشند، این می تواند دلایلی مانند خطای انسانی داشته باشد. میتوانیم از تابع is_null() از Pandas برای بررسی داده های از دست رفته استفاده کنیم و سپس از تابع sum() برای دیدن مجموع مقادیر از دست رفته در هر ستون استفاده کنیم.
| 1 df_bank.isnull().sum() |
age 0
job 0
marital 0
education 0
default 0
balance 0
housing 0
loan 0
contact 0
day 0
month 0
campaign 0
pdays 0
previous 0
poutcome 0
deposit 0
dtype: int64
از نتیجه می توان مطمئن بود که داده های ما هیچ ارزش گمشده ای ندارند و آماده ادامه دادن هستند. در مواردی که مقداری در داده های خود کم داشتید، می توانید آن را با انجام جایگزینی یا imputation حل کنید یا فقط بسته به مورد خود، ستون را به طور کلی حذف کنید. در اینجا پیوندی به یک آموزش خوب Kaggle در مورد نحوه رسیدگی به مقدار از دست رفته در مجموعه داده است.
مقیاس بندی داده های عددی
در مرحله بعد، داده های عددی خود را برای جلوگیری از حضور داده های پرت که می تواند به طور قابل توجهی بر مدل ما تأثیر بگذارد، مقیاس می کنیم. با استفاده از تابع StandardScaler() از sklearn می توانیم هر ستون خود را که حاوی داده های عددی است را مقیاس بندی کنیم. مقیاس بندی با استفاده از فرمول زیر انجام می شود:.
1 from sklearn.preprocessing import StandardScaler
2
3 # Copying original dataframe
4 df_bank_ready = df_bank.copy()
5
6 scaler = StandardScaler()
7 num_cols = [‘age’, ‘balance’, ‘day’, ‘campaign’, ‘pdays’, ‘previous’]
8 df_bank_ready[num_cols] = scaler.fit_transform(df_bank[num_cols])
9
10 df_bank_ready.head()
رمزگذاری داده های طبقه بندی شده
همانند داده های عددی، ما همچنین باید داده های طبقه بندی شده خود را از کلمات به عدد دیگر پردازش کنیم تا درک آن برای کامپیوتر آسان تر شود. برای انجام این کار از OneHotEncoder() ارائه شده توسط sklearn استفاده خواهیم کرد. اساسا یک ستون طبقه بندی را از این :

به چیزی همانند تصویر زیر تبدیل می کند:
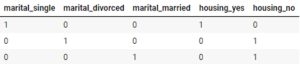
در این سلول کد، ستون برچسب خود را با جایگزینی “بله” و “نه” به ترتیب با 1 و 0 رمزگذاری می کنیم. ما می توانیم این کار را با اعمال تابع ساده lambda / in line در ستون deposit انجام دهیم.
1 from sklearn.preprocessing import OneHotEncoder
2
3 encoder = OneHotEncoder(sparse=False)
4 cat_cols = [‘job’, ‘marital’, ‘education’, ‘default’, ‘housing’, ‘loan’, ‘contact’, ‘month’, ‘poutcome’]
5
6 # Encode Categorical Data
7 df_encoded = pd.DataFrame(encoder.fit_transform(df_bank_ready[cat_cols]))
8 df_encoded.columns = encoder.get_feature_names(cat_cols)
9
10 # Replace Categotical Data with Encoded Data
11 df_bank_ready = df_bank_ready.drop(cat_cols ,axis=1)
12 df_bank_ready = pd.concat([df_encoded, df_bank_ready], axis=1)
13
14 # Encode target value
15 df_bank_ready[‘deposit’] = df_bank_ready[‘deposit’].apply(lambda x: 1 if x == ‘yes’ else 0)
16
17 print(‘Shape of dataframe:’, df_bank_ready.shape)
18 df_bank_ready.head()
تقسیم مجموعه داده برای آموزش و آزمایش
برای تکمیل مراحل پیش پردازش داده ها، داده های خود را به دو مجموعه داده، آموزش و آزمایش تقسیم می کنیم. در این حالت چون داده های کافی داریم داده ها را به ترتیب با نسبت 80:20 برای آموزش و آزمایش تقسیم می کنیم. این باعث می شود که داده های آموزشی ما دارای 8929 ردیف و 2233 ردیف برای داده های آزمایشی داشته باشند.
# Select Features
2 feature = df_bank_ready.drop(‘deposit’, axis=1)
3
4 # Select Target
5 target = df_bank_ready[‘deposit’]
6
7 # Set Training and Testing Data
8 from sklearn.model_selection import train_test_split
9 X_train, X_test, y_train, y_test = train_test_split(feature , target,
10 shuffle = True,
11 test_size=0.2,
12 random_state=1)
13
14 # Show the Training and Testing Data
15 print(‘Shape of training feature:’, X_train.shape)
16 print(‘Shape of testing feature:’, X_test.shape)
17 print(‘Shape of training label:’, y_train.shape)
18 print(‘Shape of training label:’, y_test.shape)
Shape of training feature: (8929, 50)
Shape of testing feature: (2233, 50)
Shape of training label: (8929,)
Shape of testing feature: (2233,)
مدل سازی
پس از اطمینان از اینکه داده های ما خوب و آماده ادامه دادن هستند، می توانیم به ساخت مدل خود ادامه دهیم. در این نوت بوک سعی می کنیم 4 مدل مختلف با الگوریتم های مختلف بسازیم. در این مرحله یک مدل پایه برای هر الگوریتم با استفاده از پارامتر های پیش فرض تنظیم شده توسط sklearn ایجاد میکنیم و پس از ساخت هر 4 مدل، آنها را با هم مقایسه می کنیم تا ببینیم کدام یک برای مورد ما عملکرد بهتری دارد.
برای ارزیابی مدل خود از ماتریس سردرگمی (confusion matrix) به عنوان پایه ارزیابی استفاده می کنیم.

جایی که: TP = مثبت واقعی. FP = مثبت کاذب. TN = منفی واقعی. FN = منفی کاذب می باشد.
ما از 6 معیار زیر برای ارزیابی مدل ها استفاده خواهیم کرد:
- دقت (Accuracy): نسبت نتایج واقعی در بین تعداد کل موارد بررسی شده.
![]()
- درستی (Precision): برای محاسبه اینکه چقدر از همه داده هایی که مثبت پیش بینی شده بودند واقعا مثبت هستند استفاده می شود.
![]()
- یادآوری (Recall): برای محاسبه اینکه چه نسبتی از موارد مثبت واقعی به درستی طبقه بندی شده است استفاده می شود.
![]()
- امتیاز F1 (F1 score): عددی بین 0 تا 1 می باشد و میانگین هارمونیک درستی و یادآوری است.
![]()
- امتیاز کاپا کوهن (Cohen Kappa Score): کاپا کوهن توافق بین دو ارزیاب را اندازه گیری می کند که هر کدام N مورد را در دسته های C دسته بندی می کنند که متقابلا منحصر به فرد هستند.
![]()
که در آن Po احتمال تجربی، توافق بر روی برچسب اختصاص داده شده به هر نمونه است (نسبت توافق مشاهده شده)، و Pe توافق مورد انتظار، زمانی است که هر دو حاشیه نویس برچسب ها را به طور تصادفی اختصاص می دهند. Pe با استفاده از یک پیش نویس تجربی قبل از برچسب های کلاس تخمین زده می شود.
- ناحیه زیر منحنی Area Under Curve (AUC): نشان می دهد که چقدر احتمالات از طبقات مثبت از احتمالات طبقات منفی جدا شده است.
در این مورد ما می خواهیم بر روی ارزش یادآوری مدل خود تمرکز کنیم زیرا در مشکل خود باید سعی کنیم تا آنجا که می توانیم ارزش مثبت واقعی را پیش بینی کنیم. زیرا طبقه بندی نادرست مشتریانی که واقعا می خواستند سپرده گذاری کنند، می تواند به معنای از دست دادن فرصت / درآمد باشد.
در زیر یک تابع کمکی برای ارزیابی هر مدل آموزش دیده و با معیار های ذکر شده در بالا تعریف می کنیم و امتیاز را در یک متغیر ذخیره می کنیم.
1 def evaluate_model(model, x_test, y_test):
2 from sklearn import metrics
3
4 # Predict Test Data
5 y_pred = model.predict(x_test)
6
7 # Calculate accuracy, precision, recall, f1-score, and kappa score
8 acc = metrics.accuracy_score(y_test, y_pred)
9 prec = metrics.precision_score(y_test, y_pred)
10 rec = metrics.recall_score(y_test, y_pred)
11 f1 = metrics.f1_score(y_test, y_pred)
12 kappa = metrics.cohen_kappa_score(y_test, y_pred)
13
14 # Calculate area under curve (AUC)
15 y_pred_proba = model.predict_proba(x_test)[::,1]
16 fpr, tpr, _ = metrics.roc_curve(y_test, y_pred_proba)
17 auc = metrics.roc_auc_score(y_test, y_pred_proba)
18
19 # Display confussion matrix
20 cm = metrics.confusion_matrix(y_test, y_pred)
21
22 return {‘acc’: acc, ‘prec’: prec, ‘rec’: rec, ‘f1’: f1, ‘kappa’: kappa,
23 ‘fpr’: fpr, ‘tpr’: tpr, ‘auc’: auc, ‘cm’: cm}
همانطور که در قسمت قبلی این مقاله گفتم، سعی خواهم کرد 4 مدل مختلف بسازم: درخت تصمیم گیری ، جنگل تصادفی، بیز ساده لوح و K-نزدیکترین همسایه. قبل از شروع در زیر یک تعریف ساده از هر الگوریتم و نحوه کار آنها ارائه شده است. اگر با هیچ یک از الگوریتم های گفته شده آشنا نیستید، حتما باید سعی کنید قبل از ادامه توضیحات بیشتر در مورد آنها بخوانید.
درخت تصمیم گیری
درخت تصمیم گیری یک نمودار درختی شکل است که برای تعیین مسیر عمل استفاده می شود. هر شاخه از درخت نشان دهنده یک تصمیم، وقوع یا واکنش احتمالی است.
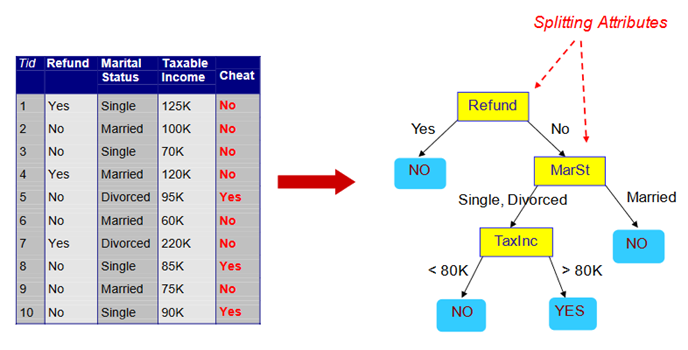
منبع: انکوباتور استعداد های دیجیتال Telkom — ماژول 5 دانشمند داده (طبقه بندی)
مزایا:
- می توان از آن برای کار های رگرسیون و طبقه بندی استفاده کرد و به راحتی می توان اهمیت نسبی را که به ویژگی های ورودی اختصاص می دهد مشاهده کرد.
- همچنین به عنوان یک الگوریتم بسیار مفید و آسان برای استفاده در نظر گرفته میشود، زیرا فرا پارامتر های پیش فرض اغلب یک نتیجه پیش بینی خوبی ایجاد می کنند.
معایب:
- بسیاری از درختان می توانند الگوریتم را برای پیش بینی های زمان واقعی کند و بی اثر کنند. یک پیش بینی دقیق تر به درختان بیشتری نیاز دارد که منجر به مدل کند تر می شود.
- این یک ابزار مدل سازی پیش بینی است و نه یک ابزار توصیفی.
جنگل تصادفی
جنگل تصادفی یا Random Decision Forest روشی است که با ساخت چندین درخت تصمیم گیری در طول مراحل آموزشی عمل می کند. تصمیم اکثریت درختان به عنوان تصمیم نهایی انتخاب می شود.
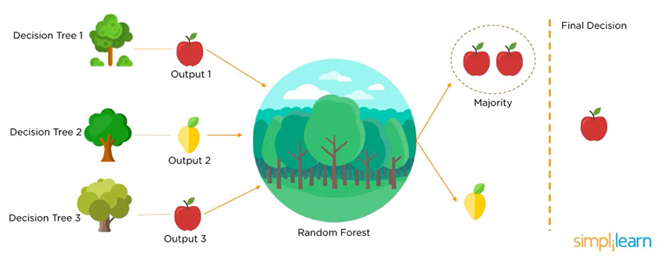
منبع: الگوریتم جنگل تصادفی (Simplilearn)
مزایا:
- می توان از آن برای کار های رگرسیون و طبقه بندی استفاده کرد و به راحتی می توان اهمیت نسبی را که به ویژگی های ورودی اختصاص می دهد مشاهده کرد.
- همچنین به عنوان یک الگوریتم بسیار مفید و آسان برای استفاده در نظر گرفته میشود، زیرا فرا پارامتر های پیشفرض اغلب یک نتیجه پیش بینی خوبی ایجاد می کنند.
معایب:
- بسیاری از درختان می توانند الگوریتم را برای پیش بینی های زمان واقعی کند و بی اثر کنند. یک پیش بینی دقیق تر به درختان بیشتری نیاز دارد که منجر به مدل کند تر می شود.
- این یک ابزار مدل سازی پیش بینی است و نه یک ابزار توصیفی.
بیز ساده لوح
بیز ساده لوح یک تکنیک ساده برای ساخت طبقه بندیکننده ها می باشد: مدل هایی که برچسب های کلاس را به نمونه های مسئله اختصاص می دهند، که به عنوان بردار مقادیر ویژگی نشان داده می شوند، جایی که برچسب های کلاس از مجموعه ای محدود ترسیم می شوند. یک الگوریتم واحد برای آموزش چنین طبقه بندیکننده هایی وجود ندارد، بلکه خانواده ای از الگوریتم ها بر اساس یک اصل مشترک وجود دارد: همه طبقه بندیکننده های بیز ساده لوح فرض می کنند که با توجه به متغیر کلاس، مقدار یک ویژگی خاص مستقل از مقدار هر ویژگی دیگری است. در تصویر زیر فرمول قضیه بیز آمده است:
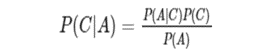
به عنوان مثال، با توجه به:
- پزشک می داند که مننژیت در 50 درصد مواقع باعث سفتی گردن می شود
- احتمال قبلی هر بیمار مبتلا به مننژیت 50000/1 است
- احتمال قبلی سفت شدن گردن هر بیمار 20/ 1 است
سپس احتمال ابتلا به مننژیت در بیمارانی که سفتی گردن دارند عبارت است از:
![]()
K-نزدیکترین همسایه ها
K-Nearest Neighbors (KNN) داده های جدید را با پیدا کردن عدد k نزدیک ترین همسایه از داده های آموزشی را طبقه بندی می کند و سپس کلاس را بر اساس اکثر همسایه های آن تعیین می کند. به عنوان مثال در تصویر زیر که k=3 اکثریت همسایه آن به عنوان B طبقه بندی شده است، اما زمانی که k=7 اکثریت به A تغییر می کند.
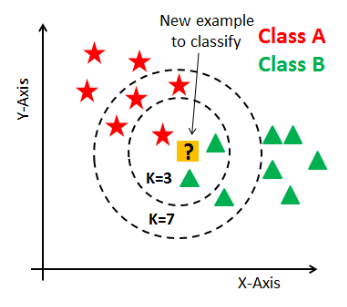
منبع: انکوباتور استعدادهای دیجیتال Telkom — ماژول 5 دانشمند داده (طبقه بندی)
مزایا:
- تکنیک ساده ای که به راحتی اجرا می شود
- مدل سازی ارزان است
- طرح طبقه بندی بسیار انعطاف پذیر می باشد
معایب:
- طبقه بندی رکورد های نا شناخته نسبتا گران است
- به محاسبه فاصله k=نزدیکترین همسایه نیاز دارد
- از نظر محاسباتی فشرده است، به خصوص زمانی که اندازه مجموعه آموزشی بزرگ می شود
- دقت را می توان به دلیل وجود ویژگی های پر سر و صدا یا نا مربوط به شدت کاهش داد
مدل سازی
پس از درک نحوه عملکرد هر مدل، بیایید سعی کنیم با استفاده از مجموعه داده آموزشی که قبلا داشتیم، مدل خود را آموزش دهیم. در زیر نمونه کدی برای مطابقت با مدل ما با استفاده از درخت تصمیم گیری وجود دارد و مدل را با تابع کمکی که قبلا ایجاد کردیم ارزیابی می کنیم. کد کامل هر الگوریتم را می توانید در این نوت بوک بیابید.
from sklearn import tree
Building Decision Tree model
dtc = tree.DecisionTreeClassifier(random_state=0)
dtc.fit(X_train, y_train)
Evaluate Model
dtc_eval = evaluate_model(dtc, X_test, y_test)
Print result
print(‘Accuracy:’, dtc_eval[‘acc’])
print(‘Precision:’, dtc_eval[‘prec’])
print(‘Recall:’, dtc_eval[‘rec’])
print(‘F1 Score:’, dtc_eval[‘f1’])
print(‘Cohens Kappa Score:’, dtc_eval[‘kappa’])
print(‘Area Under Curve:’, dtc_eval[‘auc’])
print(‘Confusion Matrix:\n’, dtc_eval[‘cm’])
مقایسه مدل
پس از ساخت تمام مدل هایمان، اکنون می توانیم عملکرد هر مدل را با هم مقایسه کنیم. برای انجام این کار ما دو نمودار ایجاد می کنیم، اول یک نمودار میله ای گروه بندی شده برای نمایش مقدار دقت، درستی، یادآوری، امتیاز f1 و کاپا مدل ما، و دوم یک نمودار خطی برای نشان دادن AUC همه مدل های ما.
1 # Intitialize figure with two plots
2 fig, (ax1, ax2) = plt.subplots(1, 2)
3 fig.suptitle(‘Model Comparison’, fontsize=16, fontweight=’bold’)
4 fig.set_figheight(7)
5 fig.set_figwidth(14)
6 fig.set_facecolor(‘white’)
7
8 # First plot
9 ## set bar size
10 barWidth = 0.2
11 dtc_score = [dtc_eval[‘acc’], dtc_eval[‘prec’], dtc_eval[‘rec’], dtc_eval[‘f1’], dtc_eval[‘kappa’]]
12 rf_score = [rf_eval[‘acc’], rf_eval[‘prec’], rf_eval[‘rec’], rf_eval[‘f1’], rf_eval[‘kappa’]]
13 nb_score = [nb_eval[‘acc’], nb_eval[‘prec’], nb_eval[‘rec’], nb_eval[‘f1’], nb_eval[‘kappa’]]
14 knn_score = [knn_eval[‘acc’], knn_eval[‘prec’], knn_eval[‘rec’], knn_eval[‘f1’], knn_eval[‘kappa’]]
15
16 ## Set position of bar on X axis
17 r1 = np.arange(len(dtc_score))
18 r2 = [x + barWidth for x in r1]
19 r3 = [x + barWidth for x in r2]
20 r4 = [x + barWidth for x in r3]
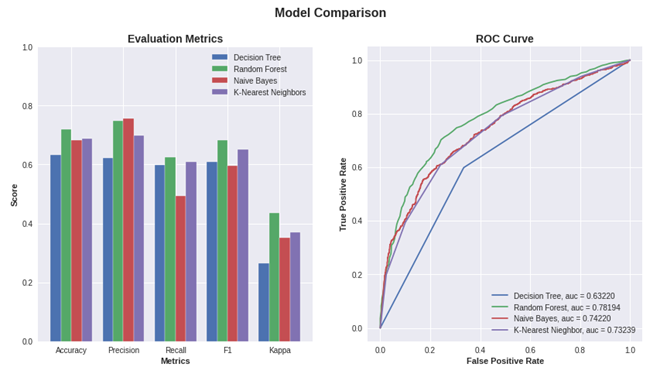
از شکل های بالا می توانیم ببینیم که مدل جنگل تصادفی ما در 5 معیار از 6 معیاری که ارزیابی می کنیم، به جز دقت، بالاتر از سایر مدل ها قرار دارد. بنابراین می توانیم فرض کنیم که جنگل تصادفی گزینه مناسبی برای حل مشکل ما می باشد.
بهینه سازی مدل
در قسمت بعدی این نوت بوک، ما سعی خواهیم کرد مدل RandomForest خود را با تنظیم فرا پارامتر های موجود در کتابخانه یادگیری scikit بهینه سازی کنیم. پس از یافتن پارامترهای بهینه، مدل جدید خود را با در نظر گرفتن مقایسه آن با مدل خط پایه قبلی خود ارزیابی خواهیم کرد.
تنظیم فرا پارامتر با GridSearchCV
ما از قابلیت GridSearchCV از sklearn برای یافتن پارامتر بهینه برای مدل خود استفاده خواهیم کرد. ما مدل پایه خود را (به نام rf_grids)، روش امتیاز دهی (در مورد ما همان طور که قبلا توضیح داده شد از فراخوانی استفاده خواهیم کرد) و همچنین مقدار پارامتر های مختلفی را که می خواهیم با مدل خود امتحان کنیم، ارائه خواهیم داد. سپس تابع GridSearchCV از طریق هر ترکیب پارامتر ها برای یافتن بهترین پارامتر های امتیاز دهی تکرار می شود.
این تابع همچنین به ما اجازه می دهد تا از اعتبار سنجی متقاطع برای آموزش مدل خود استفاده کنیم، جایی که در هر تکرار داده های ما به 5 دسته یا برابر (fold) تقسیم می شود (تعداد از روی پارامتر قابل تنظیم است). سپس مدل ها بر روی 5/4 دسته داده ها آموزش داده می شوند که از فولد یا دسته نهایی به عنوان داده اعتبار سنجی خارج می شوند، این فرآیند 5 بار تکرار می شود تا زمانی که همه فولد های ما به عنوان داده اعتبارسنجی استفاده شوند.
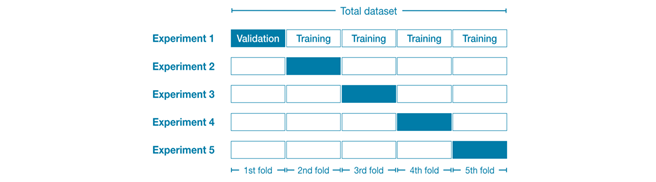
منبع: اعتبار سنجی متقابل (kaggle)
برای دیدن نتیجه اینکه کدام ترکیب پارامتر ها بهتر عمل می کند، می توانیم به ویژگی best_params_ از وسیله جستجوی شبکه خود دسترسی پیدا کنیم.
توجه: هرچه ترکیب بیشتری ارائه شود، فرآیند طولانی تر خواهد بود. همچنین، می توانید RandomizedSearchCV را امتحان کنید تا فقط به صورت تصادفی تعداد مشخصی از پارامتر ها را انتخاب کنید که می تواند منجر به زمان اجرای سریع تر شود.
1 from sklearn.model_selection import GridSearchCV
2
3 # Create the parameter grid based on the results of random search
4 param_grid = {
5 ‘max_depth’: [50, 80, 100],
6 ‘max_features’: [2, 3, 4],
7 ‘min_samples_leaf’: [3, 4, 5],
8 ‘min_samples_split’: [8, 10, 12],
9 ‘n_estimators’: [100, 300, 500, 750, 1000]
10 }
11
12 # Create a base model
13 rf_grids = RandomForestClassifier(random_state=0)
14
15 # Initiate the grid search model
16 grid_search = GridSearchCV(estimator=rf_grids, param_grid=param_grid, scoring=’recall’,
17 cv=5, n_jobs=-1, verbose=2)
18
19 # Fit the grid search to the data
20 grid_search.fit(X_train, y_train)
21
22 grid_search.best_params_
{‘max_depth’: 50,
‘max_features’: 2,
‘min_samples_leaf’: 3,
‘min_samples_split’: 8,
‘n_estimators’: 100}
ارزیابی مدل بهینه شده
پس از یافتن بهترین پارامتر برای مدل، میتوانیم به ویژگی best_estimator_ وسیله GridSearchCV دسترسی پیدا کنیم تا مدل بهینه شده خود را در متغیری به نام best_grid ذخیره کنیم. ما 6 معیار ارزیابی را با استفاده از تابع کمکی محاسبه خواهیم کرد تا آن را با مدل پایه خود در مرحله بعدی مقایسه کنیم.
# Select best model with best fit
2 best_grid = grid_search.best_estimator_
3
4 # Evaluate Model
5 best_grid_eval = evaluate_model(best_grid, X_test, y_test)
6
7 # Print result
8 print(‘Accuracy:’, best_grid_eval[‘acc’])
9 print(‘Precision:’, best_grid_eval[‘prec’])
10 print(‘Recall:’, best_grid_eval[‘rec’])
11 print(‘F1 Score:’, best_grid_eval[‘f1’])
12 print(‘Cohens Kappa Score:’, best_grid_eval[‘kappa’])
13 print(‘Area Under Curve:’, best_grid_eval[‘auc’])
14 print(‘Confusion Matrix:\n’, best_grid_eval[‘cm’])
Accuracy: 0.7174205105239588
Precision: 0.7635705669481303
Recall: 0.5926966292134831
F1 Score: 0.6673695308381655
Cohens Kappa Score: 0.42844782511519086
Area Under Curve: 0.7785737249039559
Confusion Matrix:
[[969 196]
[435 633]]
مقایسه مدل
کد زیر همان نمودار قبلی را فقط با مدل اصلی Random Forest ما و نسخه بهینه شده آن ترسیم می کند. همچنین تغییرات را در هر معیار ارزیابی چاپ می کند تا به ما در دیدن اینکه آیا مدل بهینه شده ما بهتر از مدل اصلی کار می کند یا خیر کمک کند.
Change of 0.37% on accuracy.
Change of 2.79% on precision.
Change of -3.89% on recall.
Change of -0.96% on F1 score.
Change of 0.95% on Kappa score.
Change of 0.84% on AUC.
نتایج نشان می دهد که بهینه سازی ما کمی بهتر از مدل اصلی است. مدل های بهینه سازی شده افزایشی را در 4 معیار از 6 معیار نشان می دهند، اما در سایر معیار ها، به ویژه فراخوان با منفی 3.89 درصد کاهش، عملکرد بدتری دارند. از آنجایی که می خواهیم روی پیش بینی هرچه بیشتر مقادیر مثبت واقعی تمرکز کنیم، باید به مدل اصلی خود برای پیش بینی پایبند باشیم زیرا امتیاز یادآوری بالاتری دارد.
خروجی
ما مدل خود را داریم، سپس؟ به عنوان دانشمند داده مهم است که بتوانیم مدلی با قابلیت استفاده مجدد خوب توسعه دهیم. در این بخش آخر، نحوه ایجاد یک پیش بینی بر اساس داده های جدید و همچنین نحوه ذخیره (و بارگذاری) مدل خود را با استفاده از joblib توضیح خواهم داد تا بتوانید از آن در تولید استفاده کنید یا فقط آن را برای استفاده بعدی بدون نیاز به تکرار کل روند ذخیره کنید.
پیشگویی
در این مرحله ما با استفاده از مدل جنگل تصادفی نتیجه مورد انتظار تمام سطر از مجموعه داده اصلی خود را پیش بینی می کنیم و سپس آن را برای دسترسی آسان تر در آینده در یک فایل csv ذخیره می کنیم.
1 df_bank[‘deposit_prediction’] = rf.predict(feature)
2 df_bank[‘deposit_prediction’] = df_bank[‘deposit_prediction’].apply(lambda x: ‘yes’ if x==0 else ‘no’)
3
4 # Save new dataframe into csv file
5 df_bank.to_csv(‘deposit_prediction.csv’, index=False)
6
7 df_bank.head(10)

مجموعه داده جدید با نتیجه پیش بینی شده
ذخیره مدل
ما می توانیم مدل خود را برای استفاده مجدد بیشتر از مدل ذخیره کنیم. سپس این مدل را می توان روی ماشین دیگری بارگذاری کرد تا بدون انجام مجدد کل فرآیند آموزش، پیش بینی جدیدی انجام دهد.
1 from joblib import dump, load
2
3 # Saving model
4 dump(rf, ‘bank_deposit_classification.joblib’)
5 # Loading model
6 clf = load(‘bank_deposit_classification.joblib’)
نتیجه گیری
برای یک مدل ساده می توانیم ببینیم که مدل ما در طبقه بندی داده ها به خوبی عمل کرده است. اما هنوز هم برخی از نقاط ضعف در مدل ما وجود دارد، به ویژه در متریک فراخوان نشان داده شده است که در آن ما فقط حدود 60 درصد دریافت می کنیم. این بدان معناست که مدل ما تنها قادر است 60 درصد از مشتریان بالقوه را شناسایی کند و 40 درصد دیگر را از دست بدهد. نتیجه پس از بهینه سازی مدل با استفاده از GridSearchCV تفاوت چندانی ندارد و این بدان معناست که ما با این مدل به حد خود رسیده ایم. برای بهبود عملکرد خود می توانیم الگوریتم دیگری مانند GradientBoostingClassifier را بررسی کنیم./
دیدگاهتان را بنویسید