یادگیری نظارت شده 3
یادگیری ماشینی یک زمینه مطالعه است و به الگوریتم هایی مربوط می شود که از مثال ها یاد می گیرند.
طبقه بندی وظیفه ای است که نیازمند استفاده از الگوریتم های یادگیری ماشینی است که یاد می گیرند چگونه یک برچسب طبقه را به نمونه هایی از حوزه مشکل اختصاص دهند. یک مثال آسان برای درک، طبقه بندی ایمیل ها به عنوان “هرزنامه” یا “غیر هرزنامه” است. ”
انواع مختلفی از وظایف طبقه بندی وجود دارد که ممکن است در یادگیری ماشین و رویکرد های تخصصی مدل سازی با آنها مواجه شوید که ممکن است برای هر کدام استفاده شود.
در این آموزش، انواع مختلف مدل سازی پیش بینی طبقه بندی را در یادگیری ماشینی کشف خواهید کرد.
پس از تکمیل این آموزش، خواهید دانست که:
مدل سازی پیش بینی طبقه بندی شامل تخصیص یک برچسب کلاس به نمونه های ورودی است.
طبقه بندی باینری به پیش بینی یکی از دو کلاس اشاره دارد و طبقه بندی چند کلاسه شامل پیش بینی یکی از بیش از دو کلاس است.
طبقه بندی چند برچسبی شامل پیش بینی یک یا چند کلاس برای هر مثال است و طبقه بندی نا متعادل به وظایف طبقه بندی اشاره دارد که در آن توزیع نمونه ها در بین کلاس ها برابر نیست.
پروژه خود را با کتاب جدید من تسلط بر یادگیری ماشینی با پایتون، شامل آموزش های گام به گام و فایل های کد منبع پایتون برای همه نمونه ها، شروع کنید.
بیایید شروع کنیم.
مرور کلی آموزش
این آموزش به پنج بخش تقسیم شده است، که عبارتند از:
- طبقه بندی مدل سازی پیش بینی
- طبقه بندی باینری
- طبقه بندی چند طبقه ای
- طبقه بندی چند برچسبی
- طبقه بندی نا متعادل
طبقه بندی مدل سازی پیش بینی
در یادگیری ماشین، طبقه بندی به یک مشکل مدل سازی پیش بینیکننده اشاره دارد که در آن یک برچسب کلاس برای نمونه ای از داده های ورودی پیش بینی می شود.
نمونه هایی از مشکلات طبقه بندی عبارتند از:
- با یک مثال، مشخص کنید این طبقه بندی اسپم است یا خیر.
- با توجه به یک شخصیت دست نویس، آن را به عنوان یکی از شخصیت های شناخته شده طبقه بندی کنید.
- با توجه به رفتار اخیر کاربر، به عنوان دوست یا عدم دوست طبقه بندی کنید.
از دیدگاه مدل سازی، طبقه بندی به مجموعه داده های آموزشی با نمونه های زیادی از ورودی ها و خروجی ها نیاز دارد که بتوان از آنها یاد گرفت.
یک مدل، از مجموعه داده های آموزشی استفاده می کند و نحوه نگاشت بهترین نمونه از داده های ورودی را به برچسب های کلاس خاص محاسبه می کند. به این ترتیب، مجموعه داده آموزشی باید به اندازه کافی معرف مسئله باشد و نمونه های زیادی از برچسب هر کلاس را دارا باشد.
برچسب های کلاس اغلب مقادیر رشته ای هستند، برای مثال “هرزنامه”، “غیر هرزنامه”، و باید قبل از ارائه به یک الگوریتم برای مدل سازی به مقادیر عددی نگاشت شود. این اغلب به عنوان رمزگذاری برچسب شناخته می شود، جایی که یک عدد صحیح منحصر به فرد به هر برچسب کلاس اختصاص داده می شود، “هرزنامه” = 0، “بدون هرزنامه” = 1.
انواع مختلفی از الگوریتم های طبقه بندی برای مدل سازی مسائل مدل سازی پیش بینی طبقه بندی شده وجود دارد.
هیچ نظریه خوبی در مورد نحوه نگاشت الگوریتم ها بر روی انواع مسئله وجود ندارد. در عوض، به طور کلی توصیه می شود که یک پزشک از آزمایش های کنترل شده استفاده کند و کشف کند که کدام الگوریتم و پیکر بندی الگوریتم بهترین عملکرد را برای یک کار طبقه بندی معین دارد.
الگوریتم های مدل سازی پیش بینی طبقه بندی بر اساس نتایج آنها ارزیابی می شوند. دقت طبقه بندی یک معیار رایج است که برای ارزیابی عملکرد یک مدل بر اساس برچسب های کلاس پیش بینی شده استفاده می شود. دقت طبقه بندی کامل نیست، اما نقطه شروع خوبی برای بسیاری از کار های طبقه بندی است.
به جای برچسب های کلاس، برخی از کار ها ممکن است نیاز به پیش بینی احتمال عضویت در کلاس برای هر مثال داشته باشند. این عدم قطعیت بیشتری در پیش بینی که یک برنامه کاربردی یا کاربر می تواند پس از آن تفسیر کند، ایجاد می کند. یک تشخیص رایج برای ارزیابی احتمالات پیش بینی شده، منحنی ROC است.
شاید چهار نوع اصلی از وظایف طبقه بندی وجود دارد که ممکن است با آنها روبرو شوید. آن ها عبارتند از:
- طبقه بندی باینری (Binary Classification)
- طبقه بندی چند طبقه ای (Multi-Class Classification)
- طبقه بندی چند برچسبی (Multi-Label Classification)
- طبقه بندی نا متعادل (Imbalanced Classification)
بیایید به نوبه خود به هر یک نگاه دقیق تری بیندازیم.
طبقه بندی باینری (Binary Classification)
طبقه بندی باینری به آن دسته از وظایف طبقه بندی اشاره دارد که دارای دو برچسب کلاس هستند.
مثال ها عبارتند از:
- تشخیص هرزنامه ایمیل (Email spam detection) (هرزنامه یا غیر هرزنامه).
- پیش بینی ریزش (Churn prediction) (دوست بودن یا نبودن).
- پیش بینی تبدیل (Conversion prediction) (خریدن یا نخریدن).
به طور معمول، وظایف طبقه بندی باینری شامل یک کلاس است که در حالت عادی است و کلاس دیگری که حالت غیر طبیعی است.
به عنوان مثال “غیر هرزنامه” حالت عادی است و “هرزنامه” حالت غیر عادی است. مثال دیگر این است که “سرطان شناسایی نشده است” وضعیت طبیعی یک کار است که شامل آزمایش پزشکی است و “سرطان شناسایی شده” یک حالت غیر طبیعی است.
کلاس برای حالت عادی تحت عنوان برچسب کلاس 0 و کلاس با حالت غیرعادی تحت عنوان برچسب کلاس 1 اختصاص داده می شود.
معمول است که یک کار طبقه بندی باینری را با مدلی که توزیع احتمال برنولی را برای هر مثال پیش بینی می کند، مدل کنید.
توزیع برنولی یک توزیع احتمال گسسته است که موردی را پوشش می دهد که در آن یک رویداد یک نتیجه باینری به صورت 0 یا 1 داشته باشد. برای طبقه بندی، این بدان معنی است که مدل احتمال یک مثال متعلق به کلاس 1 یا حالت غیرعادی را پیش بینی می کند.
الگوریتم های محبوبی که می توانند برای طبقه بندی باینری استفاده شوند عبارتند از:
- رگرسیون لوژیستیک
- k-نزدیکترین همسایه ها
- درختان تصمیم گیری
- ماشین بردار پشتیبانی
- بیز ساده لوح
برخی از الگوریتم ها به طور خاص برای طبقه بندی باینری طراحی شده اند و به طور بومی بیش از دو کلاس را پشتیبانی نمی کنند. به عنوان مثال می توان به ماشین های بردار پشتیبان و رگرسیون لوژیستیک اشاره کرد.
در مرحله بعد، بیایید نگاهی دقیق تر به مجموعه داده بیندازیم تا شهودی برای مشکلات طبقه بندی باینری ایجاد کنیم.
ما می توانیم از تابع () make_blobsبرای تولید مجموعه داده های طبقه بندی باینری مصنوعی استفاده کنیم.
مثال زیر مجموعه داده ای با 1000 نمونه تولید می کند که به یکی از دو کلاس تعلق دارند که هر کدام دارای دو ویژگی ورودی هستند.
اجرای مثال ابتدا مجموعه داده ایجاد شده را خلاصه می کند که 1000 نمونه تقسیم شده به عناصر ورودی (X) و خروجی (y) را نشان می دهد.
سپس توزیع برچسب های کلاس خلاصه می شود و نشان می دهد که نمونه ها به کلاس 0 یا کلاس 1 تعلق دارند و در هر کلاس 500 نمونه وجود دارد.
در مرحله بعد، 10 مثال اول در مجموعه داده خلاصه می شود، که نشان می دهد مقادیر ورودی عددی هستند و مقادیر هدف اعداد صحیح هستند که عضویت کلاس را نشان می دهند.
(1000, 2) (1000,)
Counter({0: 500, 1: 500})
[-3.05837272 4.48825769] 0
[-8.60973869 -3.72714879] 1
[1.37129721 5.23107449] 0
[-9.33917563 -2.9544469 ] 1
[-11.57178593 -3.85275513] 1
[-11.42257341 -4.85679127] 1
[-10.44518578 -3.76476563] 1
[-10.44603561 -3.26065964] 1
[-0.61947075 3.48804983] 0
[-10.91115591 -4.5772537 ] 1
در نهایت، یک نمودار پراکندگی برای متغیر های ورودی در مجموعه داده ایجاد می شود و نقاط بر اساس مقدار کلاسشان رنگ بندی می شوند.
ما می توانیم دو خوشه متمایز را ببینیم که ممکن است انتظار داشته باشیم تفکیک آنها آسان باشد.
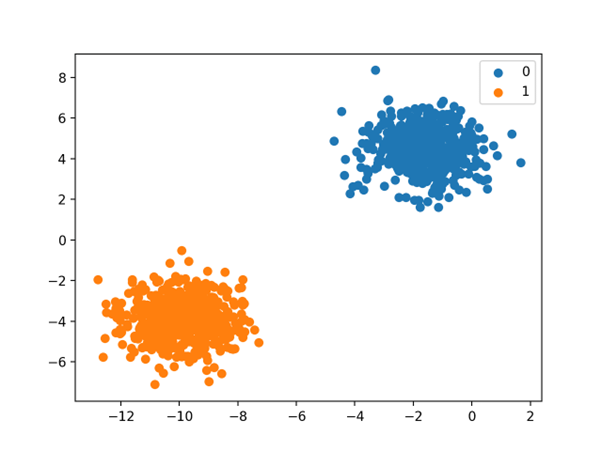
طرح پراکندگی مجموعه داده های طبقه بندی باینری.
طبقه بندی چند طبقه ای
طبقه بندی چند کلاسه به آن دسته از وظایف طبقه بندی اطلاق می شود که بیش از دو برچسب کلاس دارند.
مثال ها عبارتند از:
# example of binary classification task
from numpy import where
from collections import Counter
from sklearn.datasets import make_blobs
from matplotlib import pyplot
# define dataset
X, y = make_blobs(n_samples=1000, centers=2, random_state=1)
# summarize dataset shape
print(X.shape, y.shape)
# summarize observations by class label
counter = Counter(y)
print(counter)
# summarize first few examples
for i in range(10):
print(X[i], y[i])
# plot the dataset and color the by class label
for label, _ in counter.items():
row_ix = where(y == label)[0]
pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(label))
pyplot.legend()
pyplot.show()
- طبقه بندی چهره (Face classification)
- طبقه بندی گونه های گیاهی (Plant species classification)
- تشخیص نوری کاراکتر (Optical character recognition)
برخلاف طبقه بندی باینری، طبقه بندی چند طبقه مفهوم پیامد های عادی و غیر عادی را ندارد. در عوض، نمونه ها به عنوان متعلق به یکی از طیفی از کلاس های شناخته شده طبقه بندی می شوند.
ممکن است تعداد برچسب های کلاس در مورد برخی مشکلات بسیار زیاد باشد. برای مثال، یک مدل ممکن است یک عکس را به عنوان متعلق به یکی از هزاران یا ده ها هزار چهره در یک سیستم تشخیص چهره پیش بینی کند.
مسائلی که شامل پیش بینی دنباله ای از کلمات می شوند، مانند مدل های ترجمه متن، ممکن است نوع خاصی از طبقه بندی چند طبقه در نظر گرفته شوند. هر کلمه در توالی کلماتی که باید پیش بینی شود شامل یک طبقه بندی چند طبقه ای است که در آن اندازه واژگان تعداد کلاس های احتمالی قابل پیش بینی را مشخص می کند و می تواند ده ها یا صد ها هزار کلمه باشد.
به طور رایج یک کار طبقه بندی چند کلاسه را با مدلی که توزیع احتمال مولتی نولی (Multinoulli probability distribution) را برای هر مثال پیش بینی می کند، مدل سازی کنید.
توزیع مولتی نولی یک توزیع احتمال گسسته است که موردی را پوشش می دهد که در آن یک رویداد، یک نتیجه طبقه بندی داشته باشد، مثلا K در {1, 2, 3, …, K }. برای طبقه بندی، این بدان معنی است که مدل احتمال یک مثال متعلق به هر برچسب کلاس را پیش بینی می کند.
بسیاری از الگوریتم های مورد استفاده برای طبقه بندی باینری را می توان برای طبقه بندی چند طبقه ای استفاده کرد.
الگوریتم های محبوبی که می توانند برای طبقه بندی چند طبقه ای استفاده شوند عبارتند از:
- k-نزدیکترین همسایه ها
- درختان تصمیم گیری
- بیز ساده لوح
- جنگل تصادفی
- افزایش گرادیان
الگوریتم هایی که برای طبقه بندی باینری طراحی شده اند را می توان برای استفاده برای مسائل چند کلاسه تطبیق داد.
این شامل استفاده از استراتژی برازش چندین مدل طبقه بندی باینری برای هر کلاس در مقابل همه کلاسهای دیگر (به نام یک در مقابل بقیه یا One-vs.-Rest) یا یک مدل برای هر جفت کلاس (به نام یک در مقابل یک یا One-vs.-One) است.
- یک در مقابل بقیه: یک مدل طبقه بندی باینری را برای هر کلاس در مقابل همه کلاس های دیگر قرار دهید.
- یک در مقابل یک: برای هر جفت کلاس، یک مدل طبقه بندی باینری تنظیم کنید.
الگوریتم های طبقه بندی باینری که می توانند از این استراتژی ها برای طبقه بندی چند طبقه استفاده کنند عبارتند از:
- رگرسیون لوژیستیک
- ماشین بردار پشتیبانی
در مرحله بعد، بیایید نگاهی دقیق تر به مجموعه داده بیندازیم تا شهودی برای مسائل طبقه بندی چند طبقه ای ایجاد کنیم.
میتوانیم از تابع ()make_blobs برای تولید مجموعه داده های طبقه بندی چند کلاسه ای مصنوعی استفاده کنیم.
مثال زیر مجموعه داده ای با 1000 نمونه را ایجاد می کند که به یکی از سه کلاس تعلق دارند که هر کدام دارای دو ویژگی ورودی هستند.
# example of multi-class classification task
from numpy import where
from collections import Counter
from sklearn.datasets import make_blobs
from matplotlib import pyplot
# define dataset
X, y = make_blobs(n_samples=1000, centers=3, random_state=1)
# summarize dataset shape
print(X.shape, y.shape)
# summarize observations by class label
counter = Counter(y)
print(counter)
# summarize first few examples
for i in range(10):
print(X[i], y[i])
# plot the dataset and color the by class label
for label, _ in counter.items():
row_ix = where(y == label)[0]
pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(label))
pyplot.legend()
pyplot.show()
اجرای مثال ابتدا مجموعه داده ایجاد شده را خلاصه می کند که 1000 نمونه تقسیم شده به عناصر ورودی (X) و خروجی (y) را نشان می دهد.
سپس توزیع برچسب های کلاس خلاصه می شود و نشان می دهد که نمونه ها به کلاس 0، کلاس 1 یا کلاس 2 تعلق دارند و تقریبا 333 نمونه در هر کلاس وجود دارد.
در مرحله بعد، 10 مثال اول در مجموعه داده خلاصه می شود که نشان می دهد مقادیر ورودی عددی هستند و مقادیر هدف اعداد صحیح هستند که عضویت کلاس را نشان می دهند.
(1000, 2) (1000,)
Counter({0: 334, 1: 333, 2: 333})
[-3.05837272 4.48825769] 0
[-8.60973869 -3.72714879] 1
[1.37129721 5.23107449] 0
[-9.33917563 -2.9544469 ] 1
[-8.63895561 -8.05263469] 2
[-8.48974309 -9.05667083] 2
[-7.51235546 -7.96464519] 2
[-7.51320529 -7.46053919] 2
[-0.61947075 3.48804983] 0
[-10.91115591 -4.5772537 ] 1
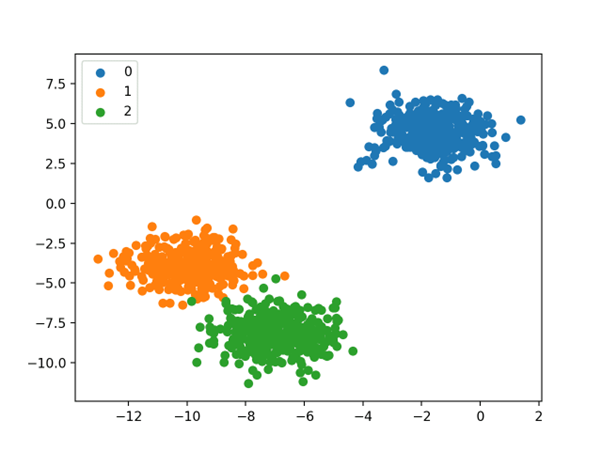
در نهایت، یک نمودار پراکندگی برای متغیر های ورودی در مجموعه داده ایجاد می شود و نقاط بر اساس مقدار کلاسشان رنگ بندی می شوند.
ما میتوانیم سه خوشه مجزا را ببینیم که ممکن است انتظار داشته باشیم تفکیک آنها آسان باشد.
طرح پراکندگی مجموعه داده های طبقه بندی چند طبقه ای
طبقه بندی چند برچسبی
طبقه بندی چند برچسبی به آن دسته از وظایف طبقه بندی اطلاق می شود که دارای دو یا چند برچسب کلاس هستند، جایی که ممکن است برای هر مثال یک یا چند برچسب کلاس پیش بینی شود.
مثال طبقه بندی عکس را در نظر بگیرید، که در آن یک عکس داده شده ممکن است چندین شی در صحنه داشته باشد و یک مدل ممکن است وجود چندین شی شناخته شده را در عکس پیش بینی کند، مانند «دوچرخه»، «سیب»، «شخص» و غیره.
این برخلاف طبقه بندی باینری و طبقه بندی چند کلاسه است که در آن یک برچسب کلاس برای هر مثال پیش بینی می شود.
به طور معمول که وظایف طبقه بندی چند برچسبی را با مدلی که چندین خروجی را پیش بینی می کند، مدل سازی کنیم که هر خروجی به عنوان توزیع احتمال برنولی پیش بینی می شود. این اساسا مدلی است که چندین پیش بینی طبقه بندی باینری را برای هر مثال انجام می دهد.
الگوریتم های طبقه بندی مورد استفاده برای طبقه بندی باینری یا چند کلاسه نمی توانند مستقیما برای طبقه بندی چند برچسبی استفاده شوند. می توان از نسخه های تخصصی الگوریتم های طبقه بندی استاندارد استفاده کرد که به آنها نسخه های چند برچسبی الگوریتم ها نیز گفته می شود، از جمله:
- درختان تصمیم گیری چند برچسبی (Multi-label Decision Trees)
- جنگل های تصادفی چند برچسبی (Multi-label Random Forests)
- تقویت گرادیان چند برچسبی (Multi-label Gradient Boosting)
روش دیگر استفاده از یک الگوریتم طبقه بندی جداگانه برای پیش بینی برچسب ها برای هر کلاس است.
در مرحله بعد، بیایید نگاهی دقیق تر به مجموعه داده بیندازیم تا شهودی برای مشکلات طبقه بندی چند برچسبی ایجاد کنیم.
ما میتوانیم از تابع ()make_multilabel_classification برای تولید یک مجموعه داده طبقه بندی چند برچسبی مصنوعی استفاده کنیم.
مثال زیر مجموعه داده ای با 1000 نمونه تولید می کند که هر کدام دارای دو ویژگی ورودی است. سه کلاس وجود دارد که هر کدام ممکن است یکی از دو برچسب (0 یا 1) را داشته باشند.
# example of a multi-label classification task
from sklearn.datasets import make_multilabel_classification
# define dataset
X, y = make_multilabel_classification(n_samples=1000, n_features=2, n_classes=3, n_labels=2, random_state=1)
# summarize dataset shape
print(X.shape, y.shape)
# summarize first few examples
for i in range(10):
print(X[i], y[i])
اجرای مثال ابتدا مجموعه داده ایجاد شده را خلاصه می کند که 1000 نمونه تقسیم شده به عناصر ورودی (X) و خروجی (y) را نشان می دهد.
در مرحله بعد، 10 مثال اول در مجموعه داده خلاصه می شود که نشان می دهد مقادیر ورودی عددی هستند و مقادیر هدف اعداد صحیح هستند که نشان دهنده عضویت برچسب کلاس هستند.
(1000, 2) (1000, 3)
[18. 35.] [1 1 1]
[22. 33.] [1 1 1]
[26. 36.] [1 1 1]
[24. 28.] [1 1 0]
[23. 27.] [1 1 0]
[15. 31.] [0 1 0]
[20. 37.] [0 1 0]
[18. 31.] [1 1 1]
[29. 27.] [1 0 0]
[29. 28.] [1 1 0]
طبقه بندی نا متعادل
طبقه بندی نا متعادل به وظایف طبقه بندی اطلاق می شود که در آن تعداد نمونه ها در هر کلاس به طور نا برابر توزیع شده است.
به طور معمول، وظایف طبقه بندی نا متعادل، وظایف طبقه بندی باینری هستند که در آن اکثر نمونه های مجموعه داده آموزشی به کلاس عادی و تعداد کمی از نمونه ها به کلاس غیرعادی تعلق دارند.
مثال ها عبارتند از:
- تشخیص کلاه برداری (Fraud detection)
- تشخیص پرت (Outlier detection)
- تست های تشخیصی پزشکی (Medical diagnostic tests)
این مشکلات به عنوان وظایف طبقه بندی باینری مدل می شوند، اگر چه ممکن است به تکنیک های تخصصی نیاز داشته باشند.
تکنیک های تخصصی ممکن است برای تغییر ترکیب نمونه ها در مجموعه داده آموزشی با کم نمونه برداری کلاس اکثریت یا بیش نمونه برداری از کلاس اقلیت استفاده شود.
مثال ها شامل:
ممکن است از الگوریتم های مدل سازی تخصصی استفاده شود که هنگام برازش مدل در مجموعه داده آموزشی، مانند الگوریتم های یادگیری ماشینی حساس به هزینه باشند و به کلاس اقلیت توجه بیشتری می کنند.
مثال های آن عبارتند از:
- رگرسیون لوژیستیک حساس به هزینه (Cost-sensitive Logistic Regression)
- درختان تصمیم گیری حساس به هزینه (Cost-sensitive Decision Trees)
- ماشین های بردار پشتیبانی حساس به هزینه (Cost-sensitive Support Vector Machines)
در نهایت، ممکن است معیار های عملکرد جایگزین مورد نیاز باشد زیرا گزارش دقت طبقه بندی ممکن است گمراه کننده باشد.
مثال ها عبارتند از:
- دقت یا درستی (Precision)
- به خاطر آوردن (Recall)
- اندازه- F(F-Measure)
در مرحله بعد، بیایید نگاهی دقیق تر به مجموعه داده بیندازیم تا شهودی برای مشکلات طبقه بندی نا متعادل ایجاد کنیم.
می توانیم از تابع ()make_classification برای تولید مجموعه داده های طبقه بندی باینری نا متعادل مصنوعی استفاده کنیم.
مثال زیر مجموعه داده ای با 1000 نمونه تولید می کند که به یکی از دو کلاس تعلق دارند که هر کدام دارای دو ویژگی ورودی هستند.
# example of an imbalanced binary classification task
from numpy import where
from collections import Counter
from sklearn.datasets import make_classification
from matplotlib import pyplot
# define dataset
X, y = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_classes=2, n_clusters_per_class=1, weights=[0.99,0.01], random_state=1)
# summarize dataset shape
print(X.shape, y.shape)
# summarize observations by class label
counter = Counter(y)
print(counter)
# summarize first few examples
for i in range(10):
print(X[i], y[i])
# plot the dataset and color the by class label
for label, _ in counter.items():
row_ix = where(y == label)[0]
pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(label))
pyplot.legend()
pyplot.show()
اجرای مثال ابتدا مجموعه داده ایجاد شده را خلاصه می کند که 1000 نمونه تقسیم شده به عناصر ورودی (X) و خروجی (y) را نشان می دهد.
سپس توزیع برچسب های کلاس خلاصه می شود و عدم تعادل شدید کلاس را با حدود 980 نمونه متعلق به کلاس 0 و حدود 20 نمونه متعلق به کلاس 1 نشان می دهد.
در مرحله بعد، 10 مثال اول در مجموعه داده خلاصه می شود که نشان می دهد مقادیر ورودی عددی هستند و مقادیر هدف اعداد صحیح هستند که عضویت کلاس را نشان می دهند. در این حالت، می توانیم ببینیم که همان طور که انتظار داریم، بیشتر نمونه ها متعلق به کلاس 0 هستند.
(1000, 2) (1000,)
Counter({0: 983, 1: 17})
[0.86924745 1.18613612] 0
[1.55110839 1.81032905] 0
[1.29361936 1.01094607] 0
[1.11988947 1.63251786] 0
[1.04235568 1.12152929] 0
[1.18114858 0.92397607] 0
[1.1365562 1.17652556] 0
[0.46291729 0.72924998] 0
[0.18315826 1.07141766] 0
[0.32411648 0.53515376] 0
در نهایت، یک نمودار پراکندگی برای متغیر های ورودی در مجموعه داده ایجاد می شود و نقاط بر اساس مقدار کلاسشان رنگ بندی می شوند.
ما می توانیم یک خوشه اصلی را برای نمونه هایی که به کلاس 0 تعلق دارند و چند نمونه پراکنده که متعلق به کلاس 1 هستند، ببینیم. تصور بر این است که مجموعه های داده با این ویژگی برچسب های کلاس نا متعادل، برای مدل سازی چالش برانگیز تر هستند.
طرح پراکندگی مجموعه داده های طبقه بندی باینری نا متعادل
دیدگاهتان را بنویسید