یادگیری نظارت شده 2
مقدمه:
• الگوریتم های طبقه بندی برای دسته بندی داده ها در یک کلاس یا دسته استفاده می شود.
• این می تواند بر روی داده های ساخت یافته یا بدون ساختار انجام شود.
• طبقه بندی می تواند سه نوع باشد: طبقه بندی دوتایی (binary classification)، طبقه بندی چند طبقه ای (multiclass classification)، طبقه بندی چند برچسبی (multilabel classification).

منبع: https://www.serokell.io
در تصویر بالا مشاهده می کنید که ایمیل ها در دسته بندی هرزنامه یا غیر اسپم قرار می گیرند. بنابراین، نمونه ای از طبقه بندی (طبقه بندی باینری) است.
الگوریتم هایی که قصد داریم به آنها بپردازیم عبارتند از:
1. رگرسیون لوژیستیک
2. بیز ساده لوح
3. K-نزدیکترین همسایه ها
4. ماشین بردار پشتیبانی
5. درخت تصمیم گیری
ما به همه الگوریتم ها با یک کد کوچک اعمال شده روی مجموعه داده آیریس (Iris) که برای کار های طبقه بندی استفاده می شود نگاه می کنیم. مجموعه داده دارای 150 نمونه (ردیف)، 4 ویژگی (ستون) است و هیچ مقدار تهی ندارد. 3 کلاس در مجموعه داده آیریس وجود دارد:
– آیریس ستوزا (Iris Setosa)
– Iris Versicolour
– آیریس ویرجینیکا (Iris Virginica)
1. رگرسیون لوژیستیک
این یک الگوریتم طبقه بندی بسیار اساسی و در عین حال مهم در یادگیری ماشینی است که از یک یا چند متغیر مستقل برای تعیین یک نتیجه استفاده می کند. رگرسیون لوژیستیک سعی می کند بهترین رابطه برازش را بین متغیر وابسته و مجموعه ای از متغیر های مستقل پیدا کند. بهترین خط برازش در این الگوریتم مانند شکل S است که در شکل زیر نشان داده شده است.
منبع: https://www.equiskill.com
مزایا:
• این یک الگوریتم بسیار ساده و کارآمد است
• واریانس کم
• امتیاز احتمال(probability) را برای مشاهدات ارائه می دهد.
معایب:
• در مدیریت تعداد زیادی از ویژگی های طبقه بندی شده عملکرد خوبی ندارد.
• فرض میکند که داده ها فاقد مقادیر گمشده هستند و پیش بینیکننده ها مستقل از یکدیگر هستند.
مثال:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import warnings
warnings.filterwarnings(‘ignore’)
from sklearn.linear_model import LogisticRegression
X, y = load_iris(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=0)
2. بیز ساده لوح
بیز ساده لوح بر اساس قضیه بیز است که یک فرض استقلال را در بین پیش بینی ها به دست می آورد. این طبقه بندی کننده فرض میکند که وجود یک ویژگی خاص در یک کلاس به وجود هیچ ویژگی/ متغیر دیگری مرتبط نیست.
دسته بندی کننده های بیز ساده لوح سه نوع هستند: بیز های ساده لوح چند جمله ای (Multinomial Naive Bayes)، بیز های ساده لوح برنولی (Bernoulli Naive Bayes)، بیز های ساده لوح گاوسی (Gaussian Naive Bayes.).
مزایا:
• این الگوریتم بسیار سریع کار می کند
• همچنین می توان از آن برای حل مسائل پیش بینی چند طبقه ای استفاده کرد زیرا برای آنها کاملا قابل استفاده می باشد.
• اگر فرض استقلال ویژگی ها برقرار باشد، این طبقه بندی کننده بهتر از سایر مدل ها با داده های آموزشی کمتر عمل می کند.
معایب:
• فرض می کند که همه ویژگی ها مستقل هستند. در حالی که این ممکن است در تئوری عالی به نظر برسد، اما در زندگی واقعی، هر کسی به سختی می تواند مجموعه ای از ویژگی های مستقل را پیدا کند.
مثال:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import GaussianNB
X, y = load_iris(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=142)
Naive_Bayes = GaussianNB()
Naive_Bayes.fit(X_train, y_train)
prediction_results = Naive_Bayes.predict(X_test)
print(prediction_results)
خروجی:
array([0, 1, 1, 2, 1, 1, 0, 0, 2, 1, 1, 1, 2, 0, 1, 0, 2, 1, 1, 2, 2, 1,0, 1, 2, 1, 2, 2, 0, 1, 2,
1, 2, 1, 2, 2, 1, 2])
These are the classes predicted for X_test data by our naive Bayes model.
3. الگوریتم K-نزدیکترین همسایه
حتما ضرب المثل معروف “کبوتر با کبوتر، باز با باز. ”را شنیده اید.
KNN بر اساس همین اصل کار می کند. این نقاط داده جدید را بسته به کلاس اکثر نقاط داده در میان همسایه K طبقه بندی می کند، جایی که K تعداد همسایه هایی است که باید در نظر گرفته شوند. KNN ایده شباهت یا the idea of similarity را به تصویر می کشد. (که گاهی اوقات فاصله، مجاورت یا نزدیکی نامیده می شود) با برخی از فرمول های فاصله ریاضی پایه مانند فاصله اقلیدسی (Euclidean distance)، فاصله منهتن (Manhattan distance) و غیره.
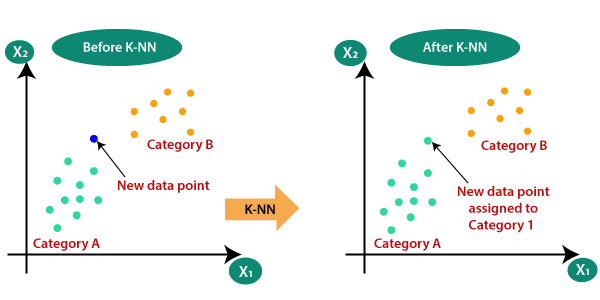
منبع: https://www.javatpoint.com
انتخاب مقدار مناسب برای K
برای انتخاب K مناسب برای داده ای که می خواهید آموزش دهید، الگوریتم KNN را چندین بار با مقادیر مختلف K اجرا کنید و آن مقدار K را که تعداد خطا های داده های دیده نشده را کاهش میدهد، انتخاب کنید.
مزایا:
• پیاده سازی KNN ساده و آسان است.
• نیازی به ساخت یک مدل، تنظیم چندین پارامتر یا فرضیات اضافی مانند برخی دیگر از الگوریتم های طبقه بندی نمی باشد.
• می توان از آن برای طبقه بندی، رگرسیون و جستجو استفاده کرد. بنابراین، انعطاف پذیر است.
معایب:
با افزایش تعداد مثال ها و / یا پیش بینی کننده ها / متغیر های مستقل، الگوریتم به طور قابل توجهی کند تر می شود.
مثال:
from sklearn.neighbors import KNeighborsClassifier
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=142)
knn = KNeighborsClassifier(n_neighbors=3)
knn.fit(X_train, y_train)
prediction_results = knn.predict(X_test[:5,:)
print(prediction_results)
خروجی:
array([0, 1, 1, 2, 1])
We predicted our results for 5 sample rows. Hence we have 5 results in array.
4. SVM
SVM مخفف عبارت Support Vector Machine می باشد. این یک الگوریتم یادگیری ماشینی نظارت شده است که اغلب برای چالش های طبقه بندی و رگرسیون استفاده می شود. با این حال، بیشتر در مسائل طبقه بندی استفاده می شود. مفهوم اصلی ماشین بردار پشتیبان و نحوه عملکرد آن را می توان با این مثال ساده به بهترین شکل درک کرد. بنابراین، فقط تصور کنید که دو برچسب دارید: سبز و آبی، و داده های ما دو ویژگی دارند: x و y. ما طبقه بندی کننده ای می خواهیم که با توجه به یک جفت مختصات (x,y)، اگر سبز یا آبی باشد، خروجی بدهد. داده های آموزشی برچسب گذاری شده را روی یک صفحه رسم کنید و سپس سعی کنید صفحه ای را پیدا کنید (هایپر صفحه ابعاد افزایش می یابد) که نقاط داده هر دو رنگ را به وضوح از هم جدا کند.
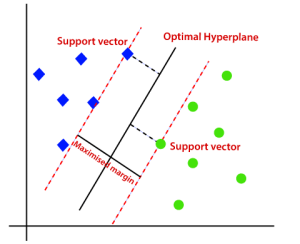
منبع: https://www.javatpoint.com
این مورد در مورد داده هایی است که خطی هستند. اما اگر داده ها غیر خطی باشند، از ترفند هسته استفاده می کنند. بنابراین، برای رسیدگی به این، ابعاد را افزایش می دهیم، این داده ها را در فضا می آورد و اکنون داده ها به صورت خطی در دو گروه قابل تفکیک می شوند.
مزایا:
SVM زمانی نسبتا خوب کار می کند که یک حاشیه واضح از جدایی بین طبقه ها وجود داشته باشد.
SVM در فضا هایی با ابعاد بالا موثرتر است.
معایب:
SVM برای مجموعه داده های بزرگ مناسب نمی باشد.
SVM زمانی که مجموعه داده نویز بیشتری دارد، یا به عبارتی دیگر وقتی کلاس های هدف با هم همپوشانی دارند عملکرد چندان خوبی ندارد. بنابراین، نیاز به رسیدگی دارد.
مثال:
from sklearn import svm
svm_clf = svm.SVC()
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=142)
svm_clf.fit(X_train, y_train)
prediction_results = svm_clf.predict(X_test[:7,:])
print(prediction_results)
خروجی:
array([0, 1, 1, 2, 1, 1, 0])
5. درخت تصمیم گیری
درخت تصمیم گیری یکی از محبوب ترین الگوریتم های یادگیری ماشینی است که استفاده می شود. از آن برای مسائل طبقه بندی و رگرسیون استفاده می شود. درختدهای تصمیم گیری از تفکر سطح انسان تقلید میکنند، بنابراین درک داده ها و ایجاد شهود و تفسیر خوب بسیار ساده است. آنها در واقع باعث می شوند که منطق تفسیر داده ها را ببینید. درخت های تصمیم گیری همانند الگوریتم های جعبه سیاه مثل SVM، شبکه های عصبی و غیره نیستند.
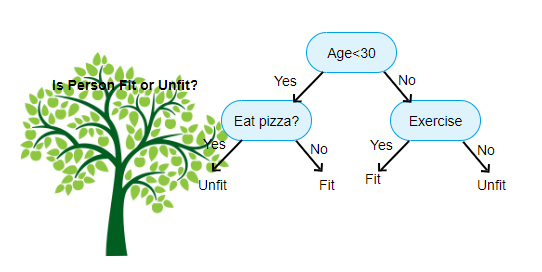
منبع: https://www.aitimejournal.com
به عنوان مثال، اگر ما فردی را به عنوان مناسب یا نامناسب طبقه بندی کنیم، درخت تصمیم گیری تا حدودی به شکل بالا در تصویر به نظر می رسد.
بنابراین، به طور خلاصه، درخت تصمیم گیری درختی است که هر گره نشان دهنده یک ویژگی / جنبه، هر شاخه نشان دهنده یک تصمیم، یک قانون، و هر برگ نشان دهنده یک نتیجه است. این نتیجه ممکن است یک مقدار مقوله ای یا پیوسته باشد. مقوله ای در صورت طبقه بندی شدن و پیوسته در موارد کاربرد های رگرسیون می باشد
مزایا:
• در مقایسه با سایر الگوریتم ها، درخت های تصمیم گیری به تلاش کمتری برای آماده سازی داده ها در حین پیش پردازش نیاز دارند.
• آنها به عادی سازی داده ها و مقیاس بندی نیز نیاز ندارند.
• مدل ساخته شده در درخت تصمیم گیری بسیار بصری است و به راحتی برای تیم های فنی و همچنین برای سهامداران توضیح داده می شود.
معایب:
• اگر حتی یک تغییر کوچک در داده ها انجام شود، می تواند منجر به تغییر بزرگی در ساختار درخت تصمیم گیری شود که باعث بی ثباتی می شود.
• گاهی اوقات محاسبه در مقایسه با الگوریتم های دیگر می تواند بسیار پیچیده تر باشد.
• درختان تصمیم گیری اغلب زمان بیشتری را برای آموزش مدل نیاز دارند.
مثال:
from sklearn import tree
dtc = tree.DecisionTreeClassifier()
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=142)
dtc.fit(X_train, y_train)
prediction_results = dtc.predict(X_test[:7,:])
print(prediction_results)
خروجی:
array([0, 1, 1, 2, 1, 1, 0])
دیدگاهتان را بنویسید