یادگیری نظارت شده 1
مقدمه
ما به عنوان انسان در طول روز تصمیمات متعددی می گیریم.
به عنوان مثال، چه زمانی بیدار شویم، چه بپوشیم، با چه کسی تماس بگیریم، از کدام مسیر برای سفر برویم، چگونه بنشینیم، و این لیست ادامه دارد. در حالی که چندین مورد از این موارد تکراری هستند و ما معمولا توجه نمی کنیم (و اجازه می دهیم به صورت ناخودآگاه انجام شود)، بسیاری دیگر وجود دارند که جدید هستند و نیاز به تفکر آگاهانه دارند.
و در طول مسیر یاد می گیریم.
کسب و کار ها، به طور مشابه، آموخته های گذشته خود را در تصمیم گیری مربوط به عملیات و ابتکارات جدید به کار میگیرند؛ برای مثال مربوط به طبقه بندی مشتریان، محصولات، و غیره است. با این حال، در اینجا کمی پیچیده تر می شود زیرا سهامداران متعددی درگیر هستند. علاوه بر این، تصمیمات به دلیل تأثیر گسترده تر آنها باید دقیق باشند.
با تکامل در فناوری دیجیتال، انسان ها دارایی های متعددی را توسعه داده اند. ماشین ها یکی از آنهاست. ما یاد گرفتهایم (و همچنان به یادگیری ادامه می دهیم) از ماشین هایی برای تجزیه و تحلیل داده ها با استفاده از آمار برای ایجاد بینش مفید استفاده کنیم که به عنوان کمکی برای تصمیم گیری و پیش بینی عمل میکند.
ماشین ها با داده ها جادو انجام نمی دهند، بلکه آمار ساده را اعمال می کنند!
در این زمینه، اجازه دهید چند الگوریتم یادگیری ماشینی که معمولا برای طبقه بندی استفاده می شوند را مرور کنیم و سعی کنیم نحوه کار و مقایسه آنها با یکدیگر را درک کنیم. اما ابتدا اجازه دهید برخی از مفاهیم مرتبط را درک کنیم.
مفاهیم اساسی
یادگیری نظارت شده به عنوان دسته ای از تجزیه و تحلیل داده ها تعریف می شود که در آن نتیجه هدف (برای مثال) تحت عنوان آیا مشتری (ها) محصولی را خریداری کرده اند یا خیر شناخته شده یا برچسب گذاری شده است. با این حال، هنگامی که مقصود گروه بندی آنها بر اساس آنچه که هر کدام خریداری کرده اند باشد، بدون نظارت می شود. این ممکن است برای بررسی رابطه بین مشتریان و آنچه خریداری می کنند انجام شود.
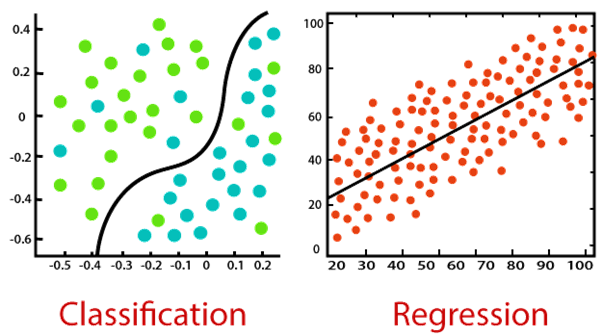
طبقه بندی و رگرسیون هر دو به یادگیری نظارت شده تعلق دارند، اما اولی در جایی اعمال می شود که نتیجه محدود است در حالی که دومی برای مقادیر نامحدود ممکن نتیجه می باشد (مثلا پیش بینی ارزش دلاری خرید).
توزیع نرمال توزیع زنگی-شکل آشنا از یک متغیر پیوسته است. این یک گسترش طبیعی از مقادیری است که یک پارامتر معمولا می گیرد.
با توجه به اینکه پیش بینی کننده ها ممکن است محدوده های مختلفی از مقادیر را داشته باشند. مثلا وزن انسان ممکن است تا 150 (کیلوگرم) باشد، اما قد معمولی فقط تا 6 (فوت) است. مقادیر نیاز به مقیاس بندی (در حدود میانگین مربوطه) دارند تا قابل مقایسه باشند.
هم خطی (Collinearity) زمانی است که 2 یا چند پیش بینی به هم مرتبط باشند. ارزش های آنها با هم حرکت می کند.
مقادیر پرت (outliners)، مقادیر استثنایی یک پیش بینی هستند که ممکن است درست باشد یا نباشد.
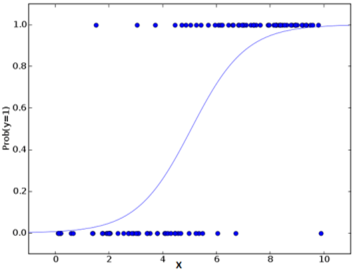
رگرسیون لوژیستیک
رگرسیون لوژیستیک از قدرت رگرسیون برای انجام طبقه بندی استفاده می کند و چندین دهه است که این کار را به خوبی انجام می دهد تا در بین محبوب ترین مدل ها باقی بماند. یکی از دلایل اصلی موفقیت مدل، قدرت توضیح پذیری آن است. به عبارتی دیگر فراخوانی سهم پیش بینی کننده های فردی، به صورت کمی.
بر خلاف رگرسیون که از حداقل مربعات استفاده می کند، مدل از حداکثر احتمال برای برازش منحنی سیگموئید بر روی توزیع متغیر هدف استفاده می کند.
با توجه به حساسیت مدل به چند خطی بودن، به کارگیری گام به گام آن رویکرد بهتری در نهایی سازی پیش بینی کننده های انتخابی مدل است.
این الگوریتم یک انتخاب محبوب در بسیاری از وظایف پردازش زبان طبیعی است. برای مثال تشخیص گفتار سمی، طبقه بندی موضوع و غیره.
شبکه های عصبی مصنوعی
شبکه های عصبی مصنوعی (ANN) سعی می کنند مغز انسان را تقلید کنند، برای مجموعه داده های بزرگ و پیچیده مناسب هستند. ساختار آنها شامل لایه (های) گره های میانی (مشابه نورون ها) است که با هم به ورودی های متعدد و خروجی هدف نگاشت می شوند.
این یک الگوریتم خود آموز است، به این صورت که با یک نقشه برداری اولیه (تصادفی) شروع می شود و پس از آن، به طور مکرر وزن های مربوطه را برای تنظیم دقیق خروجی مورد نظر برای همه رکورد ها تنظیم می کند. لایه های چندگانه قابلیت یادگیری عمیق را فراهم می کند تا بتوان ویژگی های سطح بالاتر را از داده های خام استخراج کرد.
این الگوریتم دقت پیش بینی بالایی را ارائه می کند اما باید ویژگی های عددی را مقیاس بندی کرد. کاربرد های گسترده ای در زمینه های پیش رو از جمله Computer Vision، NLP، Speech Recognition و غیره دارد.
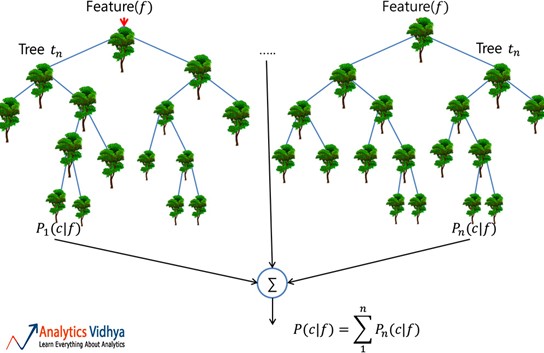
جنگل تصادفی (Random Forest)
یک جنگل تصادفی مجموعه ای قابل اعتماد از درختان تصمیم گیری متعدد (یا سبد خرید CARTs) است. اگرچه برای طبقه بندی محبوب تر از برنامه های رگرسیون است. در اینجا، درخت های منفرد از طریق کیسه بندی ساخته می شوند (یعنی تجمیع بوت استرپ ها که مجموعه داده های قطار چندگانه ایجاد شده از طریق نمونه برداری از رکورد ها با جایگزینی است) و با استفاده از ویژگی های کمتر تقسیم می شوند. جنگل متنوع حاصل از درختان غیر همبسته واریانس کاهش یافته را نشان می دهد. بنابراین، نسبت به تغییر در داده ها قوی تر است و دقت پیش بینی خود را به داده های جدید منتقل می کند.
با این حال، الگوریتم برای مجموعه داده هایی که دارای مقادیر پرت زیاد هستند، به خوبی کار نمیکند، چیزی که قبل از ساخت مدل نیاز به پرداختن دارد.
کاربرد های گسترده ای در حوزه های مالی، خرده فروشی، هوانوردی و بسیاری از حوزه های دیگر دارد.
بیز ساده لوح (Naïve Bayes)
در حالی که ممکن است متوجه این موضوع نباشیم، این الگوریتمی است که بیشتر برای غربال کردن ایمیل های هرزنامه (spam) استفاده می شود!
آن چیزی را که به عنوان احتمال پسین شناخته می شود با استفاده از قضیه بیز برای طبقه بندی داده های بدون ساختار اعمال می کند. و با انجام این کار، یک فرض ساده لوحانه ایجاد می کند که پیش بینی کننده ها مستقل هستند، که ممکن است درست نباشد.
این مدل با یک مجموعه داده آموزشی کوچک به خوبی کار میکند، مشروط بر اینکه تمام کلاس های پیش بینی کننده طبقه بندی وجود داشته باشد.
KNN
الگوریتم K – نزدیکترین همسایه (KNN) بر اساس عدد مشخص شده (k) نزدیکترین نقاط داده همسایه را پیش بینی می کند. در اینجا، پیش پردازش داده ها مهم است، زیرا به طور مستقیم بر اندازه گیری فاصله تأثیر می گذارد. بر خلاف سایر مدل ها، این مدل نه فرمول ریاضی دارد و نه توانایی توصیفی.
در اینجا، پارامتر “k” باید عاقلانه انتخاب شود. به عنوان یک مقدار کمتر از بهینه منجر به سوگیری می شود، در حالی که یک مقدار بالاتر بر دقت پیش بینی تأثیر می گذارد.
این یک مدل ساده و نسبتا دقیق است که به دلیل محاسبات بزرگی که در پیش بینی کننده های پیوسته دخیل هستند، بیشتر برای مجموعه داده های کوچکتر ترجیح داده می شود.
در یک سطح ساده، KNN ممکن است در یک تنظیم پیش بینی دو متغیره استفاده شود. مثل قد و وزن، برای تعیین جنسیت نمونه داده شده.
همه را کنار هم قرار می دهیم
عملکرد یک مدل در درجه اول به ماهیت داده ها بستگی دارد. با توجه به اینکه مجموعه داده های کسب و کار دارای چندین پیش بینیکننده هستند و پیچیده هستند، تشخیص 1 الگوریتمی که همیشه خوب کار می کند دشوار است. بنابراین، تمرین معمول این است که چندین مدل را امتحان کنید و مدل مناسب را پیدا کنید.
به عنوان یک مقایسه سطح بالا، جنبه های برجسته معمولا برای هر یک از الگوریتم های بالا یافت می شوند که در تصویر زیر بر روی چند پارامتر رایج نشان داده می شوند. برای استفاده به عنوان یک عکس فوری مرجع.
علاوه بر این، اهرم های متعددی وجود دارد؛ مثل موازنه داده، انتساب، اعتبار سنجی متقاطع، مجموعه الگوریتم ها، مجموعه داده های آموزشی بزرگتر و غیره علاوه بر تنظیم پارامتر های فوق مدل، که ممکن است برای به دست آوردن دقت مورد استفاده قرار گیرند. در حالی که دقت پیش بینی ممکن است بسیار مطلوب باشد، کسب و کار ها به دنبال پیش بینی کننده های کمک کننده برجسته (مثلا یک مدل توصیفی یا توضیح پذیری حاصل از آن) نیز هستند.
در نهایت، یادگیری ماشینی انسان ها را قادر می سازد تا به صورت کمی تصمیم بگیرند، پیش بینی کنند و فراتر از بدیهیات نگاه کنند، در حالی که گاهی اوقات به جنبه های نا شناخته قبلی نیز می رسند./
دیدگاهتان را بنویسید