یادگیری تقویتی
مقدمه
یادگیری تقویتی (RL) را می توان به عنوان مطالعه تصمیم گیری بهینه با استفاده از تجربیات تعریف کرد. یادگیری تقویتی عمدتاً برای حل یک نوع مشکل خاص در نظر گرفته شده است که در آن تصمیم گیری متوالی است و مقصود یا هدف طولانی-مدت است، که شامل رباتیک (ربات شناسی)، بازی کردن بازی های کامپیوتری، یا حتی تدارکات و مدیریت منابع است. به عبارت ساده، بر خلاف سایر الگوریتم های یادگیری ماشینی، هدف نهایی از RL این نیست که همیشه برای به دست آوردن پاداش بلا واسطه و سریع، حریص نباشید، بلکه برای حداکثر پاداش در طول فرآیند کامل آموزش بهینه سازی کنید. اگر همچنان می خواهید دانش خود را در مورد مفاهیم یادگیری تقویتی ارتقا دهید، خواندن این واژه نامه قطعا سودمند خواهد بود!
برخی از اصطلاحات ضروری قبل از شروع این موضوع:
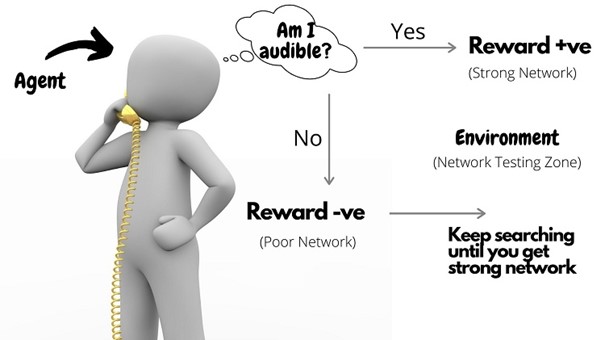
عامل (Agent): عامل در RL را می توان به عنوان موجودی تعریف کرد که به عنوان یک یادگیرنده و تصمیم گیرنده عمل می کند. این قدرت را دارد که به طور مداوم تعامل کند، اقدامات خود را انتخاب کند و به آن اقدامات پاسخ دهد.
محیط (Environment): دنیای انتزاعی است که عامل در آن حرکت می کند. محیط وضعیت و عمل فعلی عامل را به عنوان ورودی می گیرد و وضعیت بعدی و پاداش مناسب عامل را به عنوان خروجی بر می گرداند.
وضعیت ها (States): مکان مشخصی که یک عامل در آن حضور دارد وضعیت نامیده می شود. این می تواند وضعیت فعلی عامل در محیط یا هر یک از موقعیت های آینده باشد.
اقدامات (Actions): این اصطلاح مجموعه تمام حرکات ممکنی را که یک عامل می تواند در یک محیط انجام دهد را تعریف می کند.
پاداش یا جریمه (Rewards or Penalty): بازخوردی است که از طریق آن می توان موفقیت یا شکست عمل یک عامل را در یک وضعیت معین سنجید.
سیاست یا استراتژی (Policy or Strategy): عمدتاً برای ترسیم نقشه ایالت ها به همراه اقدامات آنها استفاده می شود. گفته می شود که عامل از یک استراتژی برای تعیین بهترین اقدام بعدی بر اساس وضعیت فعلی خود استفاده می کند.
الگوریتم یادگیری “Q” در RL !
تا به حال به این فکر کرده اید که از بین همه انواع الگوریتم های موجود در یادگیری تقویتی، چرا الگوریتم یادگیری Q همیشه مورد توجه بوده است؟ جواب اینجاست!
الگوریتم یادگیری Q، یک الگوریتم یادگیری بدون مدل، مبتنی بر ارزش و خارج از سیاست است.
- بدون مدل: الگوریتمی که سیاست و خط مشی بهینه خود را بدون نیاز به هیچ گونه انتقال یا پاداشی از محیط برآورد می کند.
- مبتنی بر ارزش: الگوریتم یادگیری Q، توابع ارزش خود را بر اساس معادلات به روز می کند (مثلا معادله بلمن، Bellman) به جای اینکه تابع ارزش را با یک خط مشی حریصانه تخمین بزند.
- خارج از سیاست: تابع از اقدامات خود درس می گیرد و به سیاست فعلی وابسته نیست.
با دانستن اصول پایه، بیایید اکنون با استفاده از کد ساده پایتون به قسمت پیاده سازی بپردازیم. امیدوارم با استفاده از OpenAI baselines نمونههای زیادی برای نشان دادن الگوریتم های مختلف یادگیری تقویتی مرور کرده باشید.
با این حال، این مثال می تواند توضیح واضحی در مورد عملکرد دقیق الگوریتم یادگیری Q به روشی بی دردسر به شما بدهد!
نمایش نامه – ربات ها در انبار
یک شرکت تجارت الکترونیک در حال رشد، در حال ساخت یک انبار جدید است و این شرکت مایل است تمام عملیات چیدمان یا انتخاب در انبار جدید توسط ربات های انبار انجام شود.
- در زمینه انبارداری تجارت الکترونیک، “انتخاب” به وظیفه جمع آوری اقلام مشخصی از مکان های مختلف در انبار به منظور تکمیل سفارشات مشتری است.
پس از برداشتن اقلام از قفسه ها، ربات ها باید اقلام را به مکان مشخصی در انبار بیاورند که در آنجا بتوان اقلام را برای ارسال بسته بندی کرد. به منظور اطمینان از حداکثر بازدهی و بهره-وری، ربات ها باید کوتاه ترین مسیر بین محل بسته بندی اقلام و سایر مکان های داخل انبار که ربات ها مجاز به حرکت در آن جا هستند، بیاموزند.
- ما از الگوریتم یادگیری Q برای انجام این کار استفاده خواهیم کرد!
وارد کردن کتابخانه های مورد نیاز
import libraries#
import numpy as np
تعریف محیط زیست
محیط متشکل از حالت ها، اقدامات، و پاداش ها است. حالت ها و اقدامات، ورودی هایی برای عامل الگوریتم یادگیری Q هستند، در حالی که اقدامات ممکن، خروجی های عامل هستند.
وضعیت یا حالت ها: وضعیت های محیط همه مکان های ممکن در انبار هستند. برخی از این مکان ها برای ذخیره کردن اقلام هستند (مربع های سیاه)، در حالی که سایر مکان ها راهرو هایی هستند که ربات می تواند از آن ها برای حرکت و حمل و نقل در انبار استفاده کند (مربع های سفید). مربع سبز بسته بندی و منطقه حمل و نقل اشیا مورد نظر را نشان می دهد. مربع های سیاه و سبز در جایگاه ترمینال هستند.

هدف نماینده این است که کوتاه ترین مسیر را بین منطقه بسته بندی اقلام و سایر مکان های انبار که ربات اجازه حرکت در آن جا ها را دارد، بیاموزد.
همان طور که در تصویر بالا نشان داده شده است، 121 حالت (موقعیت) ممکن در داخل انبار وجود دارد. این حالت ها در یک شبکه که شامل 11 ردیف و 11 ستون است، مرتب شده اند. بنابراین، هر مکان را می توان با شاخص سطر و ستون آن شناسایی کرد.
define the shape of the environment (i.e., its states)
environment_rows = 11
environment_columns = 11
Create a 3D numpy array to hold the current Q-values for each state and action pair: Q(s, a)
#The array contains 11 rows and 11 columns (to match the shape of the environment), as well as a third “action” dimension.
#The “action” dimension consists of 4 layers that will allow us to keep track of the Q-values for each possible action in
#each state (see next cell for a description of possible actions).
#The value of each (state, action) pair is initialized to 0.
q_values = np.zeros((environment_rows, environment_columns, 4))
اقدامات:
اقدامات یا عمل هایی که برای عامل در دسترس است، حرکت دادن ربات در یکی از چهار جهت است:
- بالا
- سمت راست
- پایین
- سمت چپ
بدیهی است که عامل باید بیاموزد که از حرکت در مکان های نگهداری اقلام (مانند قفسهها) اجتناب کند!
define actions
numeric action codes: 0 = up, 1 = right, 2 = down, 3 = left
actions = [‘up’, ‘right’, ‘down’, ‘left’]
پاداش ها:
آخرین مؤلفه محیطی که باید تعریف کنیم، پاداش است. برای کمک به عامل در یادگیری، به هر وضعیت (محل) در انبار یک پاداش با ارزشی اختصاص داده می شود. عامل ممکن است از هر مربع سفیدی شروع کند، اما هدفش همیشه یکسان است: به حداکثر رساندن مجموع پاداش هایش! پاداش های منفی (یعنی مجازات ها) برای همه وضعیت ها به جز هدف استفاده می شود.
- این کار عامل را تشویق می کند تا با به حداقل رساندن مجازات ها ، کوتاه ترین مسیر را برای رسیدن به هدف شناسایی کند.
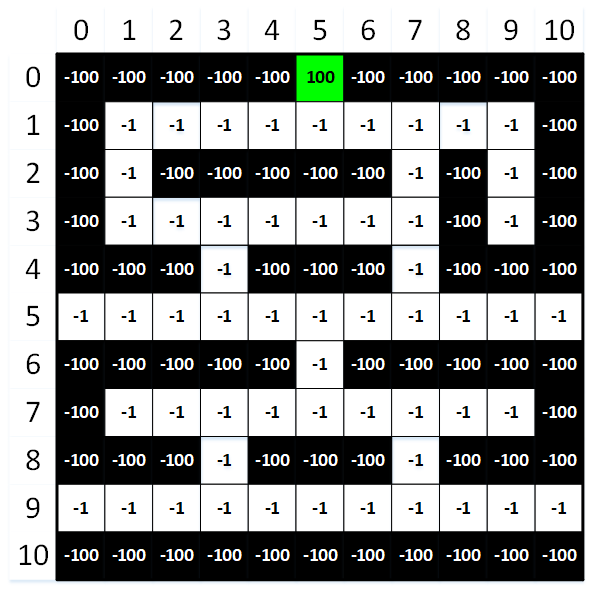
عامل، برای به حداکثر رساندن پاداش های انباشته (با به حداقل رساندن مجازات های انباشته شده اش) باید کوتاه ترین مسیرها را بین محل بسته بندی اقلام (مربع سبز) و سایر مکان های انبار که ربات مجاز به حرکت در آن ها است (مربع سفید) را پیدا کند. همچنین عامل باید یاد بگیرد که از تصادف با هر یک از مکان های ذخیره اقلام (مربع سیاه) جلوگیری کند!
#Create a 2D numpy array to hold the rewards for each state.
#The array contains 11 rows and 11 columns (to match the shape of the environment), and each value is initialized to -100.
rewards = np.full((environment_rows, environment_columns), -100.)
rewards[0, 5] = 100. #set the reward for the packaging area (i.e., the goal) to 100
#define aisle locations (i.e., white squares) for rows 1 through 9
aisles = {} #store locations in a dictionary
aisles[1] = [i for i in range(1, 10)]
aisles[2] = [1, 7, 9]
aisles[3] = [i for i in range(1, 8)]
aisles[3].append(9)
aisles[4] = [3, 7]
aisles[5] = [i for i in range(11)]
aisles[6] = [5]
aisles[7] = [i for i in range(1, 10)]
aisles[8] = [3, 7]
aisles[9] = [i for i in range(11)]
#set the rewards for all aisle locations (i.e., white squares)
for row_index in range(1, 10):
for column_index in aisles[row_index]:
rewards[row_index, column_index] = -1.
#print rewards matrix
for row in rewards:
print(row)
خروجی:
[-100. -100. -100. -100. -100. 100. -100. -100. -100. -100. -100.]
[-100. -1. -1. -1. -1. -1. -1. -1. -1. -1. -100.]
[-100. -1. -100. -100. -100. -100. -100. -1. -100. -1. -100.]
[-100. -1. -1. -1. -1. -1. -1. -1. -100. -1. -100.]
[-100. -100. -100. -1. -100. -100. -100. -1. -100. -100. -100.]
[-1. -1. -1. -1. -1. -1. -1. -1. -1. -1. -1.]
[-100. -100. -100. -100. -100. -1. -100. -100. -100. -100. -100.]
[-100. -1. -1. -1. -1. -1. -1. -1. -1. -1. -100.]
[-100. -100. -100. -1. -100. -100. -100. -1. -100. -100. -100.]
[-1. -1. -1. -1. -1. -1. -1. -1. -1. -1. -1.]
[-100. -100. -100. -100. -100. -100. -100. -100. -100. -100. -100.]
آموزش مدل:
وظیفه بعدی عامل ما این است که با پیاده سازی یک مدل یادگیری Q در مورد محیط خود بیاموزد. فرآیند یادگیری این مراحل را دنبال خواهد کرد:
- برای شروع این قسمت جدید، یک حالت تصادفی و بی انتها (مربع سفید) را برای عامل انتخاب کنید.
- یک عمل (حرکت به بالا، راست، پایین یا چپ) را برای وضعیت فعلی انتخاب کنید. اقدامات با استفاده از یک الگوریتم حریص اپسیلون “epsilon greedy algorithm“ انتخاب خواهند شد. این الگوریتم معمولاً امیدوار کننده ترین اقدام را برای عامل انتخاب میکند، اما گاهی اوقات یک گزینه کمتر امیدوار کننده را انتخاب میکند تا عامل را تشویق به کاوش در محیط کند.
- عمل انتخاب شده را انجام دهید و به حالت بعدی انتقال دهید (یعنی به مکان بعدی بروید).
- پاداش حرکت به حالت جدید را دریافت کنید و تفاوت زمانی را محاسبه کنید.
- ارزش Q (Q-value) را برای حالت و عمل قبلی به روز کنید.
- اگر حالت جدید (جاری) حالت پایانی است، به شماره 1# بروید. در غیر این صورت به شماره 2# بروید.
کل این روند در 1000 قسمت تکرار خواهد شد. این روند به عامل فرصت کافی برای یادگیری کوتاه ترین مسیرها بین منطقه بسته بندی اقلام و سایر مکان های موجود در انبار که ربات مجاز به حرکت است را می دهد، در عین حال از برخورد ربات با هر یک از مکان های نگهداری اقلام جلوگیری میکند.
تعریف توابع کمکی
#define a function that determines if the specified location is a terminal state
def is_terminal_state(current_row_index, current_column_index):
#if the reward for this location is -1, then it is not a terminal state (i.e., it is a ‘white square’)
if rewards[current_row_index, current_column_index] == -1.:
return False
else:
return True
#define a function that will choose a random, non-terminal starting location
def get_starting_location():
#get a random row and column index
current_row_index = np.random.randint(environment_rows)
current_column_index = np.random.randint(environment_columns)
#continue choosing random row and column indexes until a non-terminal state is identified
#(i.e., until the chosen state is a ‘white square’).
while is_terminal_state(current_row_index, current_column_index):
current_row_index = np.random.randint(environment_rows)
current_column_index = np.random.randint(environment_columns)
return current_row_index, current_column_index
#define an epsilon greedy algorithm that will choose which action to take next (i.e., where to move next)
def get_next_action(current_row_index, current_column_index, epsilon):
#if a randomly chosen value between 0 and 1 is less than epsilon,
#then choose the most promising value from the Q-table for this state.
if np.random.random() < epsilon:
return np.argmax(q_values[current_row_index, current_column_index])
else: #choose a random action
return np.random.randint(4)
#define a function that will get the next location based on the chosen action
def get_next_location(current_row_index, current_column_index, action_index):
new_row_index = current_row_index
new_column_index = current_column_index
if actions[action_index] == ‘up’ and current_row_index > 0:
new_row_index -= 1
elif actions[action_index] == ‘right’ and current_column_index < environment_columns – 1:
new_column_index += 1
elif actions[action_index] == ‘down’ and current_row_index < environment_rows – 1:
new_row_index += 1
elif actions[action_index] == ‘left’ and current_column_index > 0:
new_column_index -= 1
return new_row_index, new_column_index
Define a function that will get the shortest path between any location within the warehouse that
#the robot is allowed to travel and the item packaging location.
def get_shortest_path(start_row_index, start_column_index):
#return immediately if this is an invalid starting location
if is_terminal_state(start_row_index, start_column_index):
return []
else: #if this is a ‘legal’ starting location
current_row_index, current_column_index = start_row_index, start_column_index
shortest_path = []
shortest_path.append([current_row_index, current_column_index])
#continue moving along the path until we reach the goal (i.e., the item packaging location)
while not is_terminal_state(current_row_index, current_column_index):
#get the best action to take
action_index = get_next_action(current_row_index, current_column_index, 1.)
#move to the next location on the path, and add the new location to the list
current_row_index, current_column_index = get_next_location(current_row_index, current_column_index, action_index)
shortest_path.append([current_row_index, current_column_index])
return shortest_path
عامل را با استفاده از الگوریتم یادگیری Q آموزش دهید
#define training parameters
epsilon = 0.9 #the percentage of time when we should take the best action (instead of a random action)
discount_factor = 0.9 #discount factor for future rewards
learning_rate = 0.9 #the rate at which the agent should learn
#run through 1000 training episodes
for episode in range(1000):
#get the starting location for this episode
row_index, column_index = get_starting_location()
#continue taking actions (i.e., moving) until we reach a terminal state
#(i.e., until we reach the item packaging area or crash into an item storage location)
while not is_terminal_state(row_index, column_index):
#choose which action to take (i.e., where to move next)
action_index = get_next_action(row_index, column_index, epsilon)
#perform the chosen action, and transition to the next state (i.e., move to the next location)
old_row_index, old_column_index = row_index, column_index #store the old row and column indexes
row_index, column_index = get_next_location(row_index, column_index, action_index)
#receive the reward for moving to the new state, and calculate the temporal difference
reward = rewards[row_index, column_index]
old_q_value = q_values[old_row_index, old_column_index, action_index]
temporal_difference = reward + (discount_factor * np.max(q_values[row_index, column_index])) – old_q_value
#update the Q-value for the previous state and action pair
new_q_value = old_q_value + (learning_rate * temporal_difference)
q_values[old_row_index, old_column_index, action_index] = new_q_value
print(‘Training complete!’)
خروجی:
آموزش تکمیل شد.
کوتاه ترین مسیرها را پیدا کنید
حالا که عامل به طور کامل آموزش دیده است، می توانیم ببینیم با نمایش کوتاه ترین مسیر بین هر مکان در انبار که ربات مجاز به حرکت است و همچنین در محل بسته بندی اقلام، چه آموخته است.
شروع از چند مکان مختلف را امتحان کنید!
#display a few shortest paths
print(get_shortest_path(3, 9)) #starting at row 3, column 9
print(get_shortest_path(5, 0)) #starting at row 5, column 0
print(get_shortest_path(9, 5)) #starting at row 9, column 5
خروجی:
[[3, 9], [2, 9], [1, 9], [1, 8], [1, 7], [1, 6], [1, 5], [0, 5]]
[[5, 0], [5, 1], [5, 2], [5, 3], [4, 3], [3, 3], [3, 4], [3, 5], [3, 6], [3, 7], [2, 7], [1, 7], [1, 6], [1, 5], [0, 5]]
[[9, 5], [9, 6], [9, 7], [8, 7], [7, 7], [7, 6], [7, 5], [6, 5], [5, 5], [5, 6], [5, 7], [4, 7], [3, 7], [2, 7], [1, 7], [1, 6], [1, 5], [0, 5]]
در نهایت…؛
این عالی است که ربات ما به طور خودکار می تواند کوتاه ترین مسیر را از هر محل “قانونی” در انبار به محل بسته بندی اقلام انتخاب کند. اما در مورد نمایشنامه (سناریو) ی مخالف چی؟
قرار دادن متفاوت، ربات ما در حال حاضر می تواند یک اشیا از هر نقطه در انبار را به منطقه بسته بندی تحویل دهد، اما پس از ارائه آن اشیا، ربات باید از منطقه بسته بندی به محل دیگری در انبار برای برداشتن اقلام بعدی مسیری را طی کند!
نگران نباشید – این مشکل به سادگی با برگرداندن ترتیب کوتاه ترین مسیر حل می شود!
#display an example of reversed shortest path
path = get_shortest_path(5, 2) #go to row 5, column 2
path.reverse()
print(path)
خروجی:
[[0, 5], [1, 5], [1, 6], [1, 7], [2, 7], [3, 7], [3, 6], [3, 5], [3, 4], [3, 3], [4, 3], [5, 3], [5, 2]]
دیدگاهتان را بنویسید