مقادیر از دست رفته
مقدمه
درون یابی تکنیکی در پایتون است که برای تخمین نقاط داده نا شناخته بین دو نقطه داده شناخته شده استفاده می شود. درون یابی بیشتر برای نسبت دادن مقادیر از دست رفته در چارچوب یا سری های داده در حین پیش پردازش داده ها استفاده می شود.
از درون یابی در پردازش تصویر نیز استفاده می شود، هنگامی که یک تصویر را گسترش می دهید، می توانید مقدار پیکسل را با کمک پیکسل های همسایه تخمین بزنید.
فهرست مطالب
- چه زمانی از درون یابی یا Interpolation استفاده کنیم؟
- درون یابی برای پر کردن مقادیر از دست رفته در سری داده ها
- درون یابی خطی
- درون یابی چند جمله ای
- درون یابی از طریق padding (پر کردن جای خالی)
- درون یابی برای پر کردن مقادیر از دست رفته در چارچوب داده
- روش خطی
- جهت عقب
- درون یابی از طریق padding
- پر کردن مقادیر از دست رفته در سری داده های زمانی
- پی نوشت
زمان استفاده از درون یابی
ما می توانیم از درون یابی برای یافتن مقدار گمشده با کمک همسایگان آن استفاده کنیم. وقتی که مقادیر گمشده با میانگین به بهترین وجه مطابقت ندارد، باید به تکنیک دیگری برویم و تکنیکی که بیشتر مردم پیدا میکنند درون یابی است.
درون یابی بیشتر هنگام کار با داده های زمانی سری استفاده می شود زیرا در داده های زمانی سری ما دوست داریم مقادیر گم شده را با یک یا دو مقدار قبلی پر کنیم. برای مثال، فرض کنید دما، اکنون ما همیشه ترجیح می دهیم دمای امروز را با میانگین 2 روز گذشته پر کنیم، نه با میانگین ماه. همچنین می توانیم از درون یابی برای محاسبه میانگین متحرک استفاده کنیم.
استفاده از درون یابی برای پر کردن مقادیر از دست رفته در داده های سری
سری pandas یک آرایه تک بعدی است که قادر به ذخیره عناصر انواع داده های مختلف مانند لیست می باشد. ما به راحتی می توانیم با کمک یک لیست، چند تایی(tuple) یا فرهنگ لغت، سری ایجاد کنیم. برای انجام تمام روش های درون یابی، یک سری pandas با مقادیر NaN ایجاد میکنیم و سعی میکنیم مقادیر از دست رفته را با روش های مختلف درون یابی پر کنیم.
import pandas as pd
import numpy as np
a = pd.Series([0, 1, np.nan, 3, 4, 5, 7])
1) درون یابی خطی
درون یابی خطی به سادگی به معنای تخمین مقدار گمشده با اتصال نقاط در یک خط مستقیم به ترتیب افزایش است. به طور خلاصه، مقدار مجهول را به همان ترتیب افزایشی از مقادیر قبلی تخمین می زند. روش پیش فرض استفاده شده توسط درون یابی، خطی است، بنابراین هنگام اعمال آن، نیازی به تعیین آن نداریم.
a.interpolate()
خروجی که می توانید مشاهده کنید؛ تحت عنوان:
0 0.0
1 1.0
2 2.0
3 3.0
4 4.0
5 5.0
6 7.0
بنابراین، درون یابی خطی به همین ترتیب کار می کند. به یاد داشته باشید که با استفاده از شاخص تفسیر نمی کند، بلکه با اتصال نقاط در یک خط مستقیم، مقادیر را تفسیر می کند.
2) درون یابی چند جمله ای
در درون یابی چند جمله ای باید یک ترتیب را مشخص کنید. این بدان معناست که درون یابی چند جمله ای مقادیر گم شده را با کمترین درجه ممکن پر می کند که از نقاط داده موجود می گذرد. منحنی درون یابی چند جمله ای مانند منحنی سینوس مثلثاتی است یا آن را مانند یک سهمی فرض می کند.
a.interpolate(method=”polynomial”, order=2)
اگر ترتیبی را به عنوان 1 ارسال کنید، خروجی مشابه خطی خواهد بود زیرا چند جمله ای ترتیبی 1، خطی است.
3) درون یابی از طریق padding
درون یابی با کمک padding به معنای پر کردن مقادیر از دست رفته با همان مقدار موجود در بالای آنها در مجموعه داده است. اگر مقدار از دست رفته در ردیف اول باشد، این روش کار نخواهد کرد. در حین استفاده از این تکنیک، باید حدی (limit) را نیز مشخص کنید که به معنای پر کردن مقدار NaN است.
بنابراین، اگر روی یک پروژه دنیای واقعی کار می کنید و می خواهید مقادیر از دست رفته را با مقادیر قبلی پر کنید، باید محدودیت تعداد ردیف های مجموعه داده را مشخص کنید.
a.interpolate(method=”pad”, limit=2)
خروجی را به صورت زیر خواهید دید.
0 0.0
1 1.0
2 1.0
3 3.0
4 4.0
5 5.0
6 7.0
مقدار گم شده با همان مقداری که قبلا برای آن وجود داشت جایگزین می شود.
استفاده از درون یابی برای پر کردن مقادیر از دست رفته در چارچوب داده pandas
DataFrame یا چارچوب داده یک ساختار داده پایتون است که داده ها را به شکل سطر و ستون ذخیره می کند. هنگام انجام تجزیه و تحلیل داده ها، ما همیشه داده ها را در جدولی ذخیره می کنیم که به عنوان چارچوب داده شناخته می شود. چارچوب داده می تواند حاوی مقادیر زیادی از داده های از دست رفته در بسیاری از ستون ها باشد، بنابراین اجازه دهید بفهمیم چگونه می توانیم از درون یابی برای پر کردن مقادیر از دست رفته در چارجوب داده استفاده کنیم.
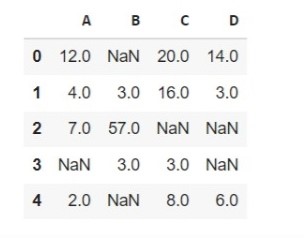
1) درون یابی خطی در جهت ارسال یا جلو
روش خطی، شاخص را نادیده می گیرد و مقادیر از دست رفته را با فواصل مساوی در نظر می گیرد و بهترین نقطه را برای مطابقت با مقدار از دست رفته پس از نقاط قبلی پیدا می کند. اگر مقدار از دست رفته در ابتدا شاخص باشد، آن را به عنوان Nan باقی می گذارد. بیایید آن را در چارچوب داده خود اعمال کنیم.
df.interpolate(method =’linear’, limit_direction =’forward’)
خروجی را می توانید در شکل زیر مشاهده کنید.
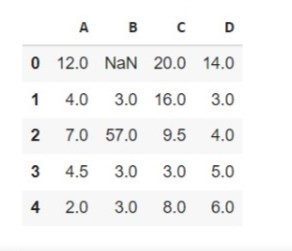
درون یابی رو به جلو.
اگر فقط می خواهید درون یابی را در یک ستون انجام دهید، آن هم ساده است و از کد زیر پیروی می کند.
df[‘C’].interpolate(method=”linear”)
2) درون یابی خطی در جهت عقب
حال روش یکسان است، فقط ترتیبی که می خواهیم انجام دهیم تغییر می کند. اکنون این روش از انتهای چارچوب داده کار می کند یا آن را به عنوان یک رویکرد پایین به بالا درک می کند.
df.interpolate(method =’linear’, limit_direction =’backward’)
همان خروجی شکل زیر را دریافت خواهید کرد.
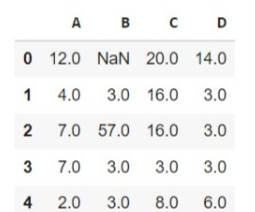
3) درون یابی با استفاده از padding
قبلا مشاهده کردیم که برای استفاده از padding باید حد مقادیر NaN را که باید پر شود، مشخص کنیم. ما حداکثر 2 مقدار NaN در چارچوب داده داریم بنابراین حد ما 2 خواهد بود.
df.interpolate(method=”pad”, limit=2)
پس از اجرای کد بالا، مقادیر از دست رفته را با مقادیر فعلی قبلی پر می شود و خروجی مطابق شکل زیر ارائه داده می شود.
پر کردن مقادیر از دست رفته در داده های زمانی سری
داده های زمانی سری داده هایی هستند که از روند یا نوسانات فصلی خاصی پیروی می کنند. تجزیه و تحلیل داده های زمانی سری کمی با چارچوب های داده معمولی متفاوت است. هر زمان که داده های زمانی سری داشته باشیم، برای مقابله با مقادیر از دست رفته نمی توانیم از تکنیک های انتساب میانگین استفاده کنیم. درون یابی یک روش قدرتمند برای پر کردن مقادیر از دست رفته در داده های زمانی سری می باشد.
= pd.DataFrame({‘Date’: pd.date_range(start=’2021-07-01′, periods=10, freq=’H’), ‘Value’:range(10)})
df.loc[2:3, ‘Value’] = np.nan
پر کردن مقادیر از دست رفته در روش ارسال رو به جلو و عقب (Forwarding و Backward)
ساده ترین روش برای پر کردن مقادیر با استفاده از درون یابی، همان روشی است که در ستونی از چارچوب داده اعمال می کنیم.
df[‘value’].interpolate(method=”linear”)
اما زمانی که ستون تاریخ داریم از این روش استفاده نمی شود زیرا مقادیر از دست رفته را بر اساس تاریخ پر می کنیم که در عین پر کردن مقادیر از دست رفته در داده های زمانی سری منطقی است.
df.set_index(‘Date’)[‘Value’].interpolate(method=”linear”)
از همان کد با اعمال چند تغییر می توان به عنوان یک پر کننده برای پر کردن مقادیر از دست رفته در جهت عقب استفاده کرد.
df.set_index(‘Date’)[‘Value’].fillna(method=”backfill”, axis=None)
پی نوشت
ما روش های مختلفی برای استفاده از تابع درون یابی در پایتون برای پر کردن مقادیر از دست رفته به صورت سری و همچنین در چارچوب داده یاد گرفته ایم. درون یابی در بیشتر موارد بهترین تکنیک برای پر کردن مقادیر از دست رفته است.
دیدگاهتان را بنویسید