داده های پرت 1
5 روش برای تشخیص نقاط پرت / ناهنجاری ها که هر دانشمند داده باید بداند (کد پایتون)
تشخیص ناهنجاری ها برای هر کسب و کاری حیاتی است، چه از طریق شناسایی عیوب یا فعال بودن. این مقاله 5 روش مختلف برای شناسایی آن ناهنجاری ها را مورد بحث قرار می دهد.
ناهنجاری / پرت چیست؟
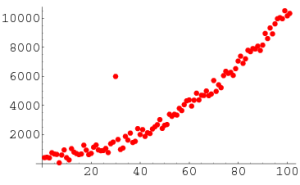
در آمار، نقاط پرت داده هایی هستند که به جمعیت خاصی تعلق ندارند. این یک مشاهده غیر عادی است که بسیار دور تر از سایر ارزش ها قرار دارد. نقطه پرت، مشاهده ای است که از داده های به خوبی ساختار یافته دیگر، متفاوت است.
به عنوان مثال، شما می توانید به وضوح در این لیست مقدار پرت را ببینید: [20,24,22,19,29,18,4300,30,18]
وقتی مشاهدات فقط یک دسته اعداد هستند و یک بعدی هستند، تشخیص آن ها آسان است، اما وقتی هزاران مشاهده یا به صوت چند بعدی دارید، به روش های هوشمندانه تری برای تشخیص آن مقادیر نیاز خواهید داشت. این موضوعی است که این مقاله به آن خواهد پرداخت.
چرا ما به ناهنجاری ها اهمیت می دهیم؟
تشخیص نقاط پرت یا ناهنجاری ها یکی از مشکلات اصلی در داده کاوی است. گسترش نو ظهور و رشد مداوم داد هها و گسترش دستگاه های اینترنت اشیا، ما را وادار میکند در نحوه برخورد با ناهنجاری ها و موارد استفاده که می توان با نگاه کردن به آن، ناهنجاری ها ایجاد کرد، تجدید نظر کنیم.
ما اکنون ساعت ها و مچ بند های هوشمندی داریم که می توانند هر چند دقیقه ضربان قلب ما را تشخیص دهند. تشخیص ناهنجاری ها در داده های ضربان قلب می تواند به پیش بینی بیماری های قلبی کمک کند. ناهنجاری در الگو های ترافیکی می تواند به پیش بینی تصادفات کمک کند. همچنین می توان از آن برای شناسایی تنگنا ها در زیر ساخت شبکه و ترافیک بین سرور ها استفاده کرد. از این رو، موارد استفاده و راه حل ساخته شده در مورد تشخیص ناهنجاری ها نامحدود است.
دلیل دیگری که چرا باید ناهنجاری ها را شناسایی کنیم این است که هنگام آماده سازی مجموعه های داده برای مدل های یادگیری ماشینی، تشخیص همه موارد پرت و خلاص شدن از آن ها یا تجزیه و تحلیل آن ها برای اینکه بدانید در وهله اول چرا آن ها را داشتید، واقعا مهم است.
اکنون، بیایید 5 روش رایج برای تشخیص ناهنجاری ها را با ساده ترین راه بررسی کنیم.
روش 1 – انحراف معیار:
در آمار، اگر توزیع دادهها تقریبا نرمال باشد، حدود 68 درصد از مقادیر داده ها در یک انحراف استاندارد از میانگین، و حدود 95 درصد در دو انحراف استاندارد، و حدود 99.7 درصد در سه انحراف استاندارد قرار دارند.
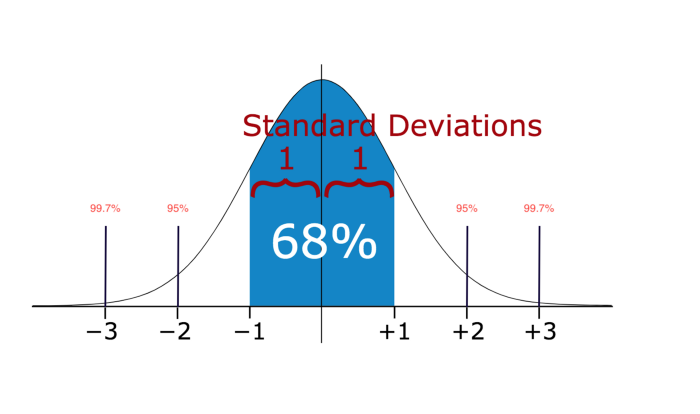
بنابراین، اگر هر نقطه داده ای دارید که بیش از 3 برابر انحراف معیار باشد، آن نقاط به احتمال زیاد غیر عادی یا پرت هستند.
بیایید کد هایی را ببینیم.
1 import numpy as np
2 import matplotlib.pyplot as plt
3 seed(1)
4
5
6 # multiply and add by random numbers to get some real values
7 data = np.random.randn(50000) * 20 + 20
8
9 # Function to Detection Outlier on one-dimentional datasets.
10 def find_anomalies(data):
11 #define a list to accumlate anomalies
12 anomalies = []
13
14 # Set upper and lower limit to 3 standard deviation
15 random_data_std = std(random_data)
16 random_data_mean = mean(random_data)
17 anomaly_cut_off = random_data_std * 3
18
19 lower_limit = random_data_mean – anomaly_cut_off
20 upper_limit = random_data_mean + anomaly_cut_off
21 print(lower_limit)
خروجی این کد لیستی از مقادیر بالای 80 و زیر منفی 40 است. توجه داشته باشید که مجموعه داده ای که من ارسال می کنم یک مجموعه داده یک بعدی است. اکنون، بیایید روش های پیشرفته تری را برای مجموعه داده های چند بعدی بررسی کنیم.
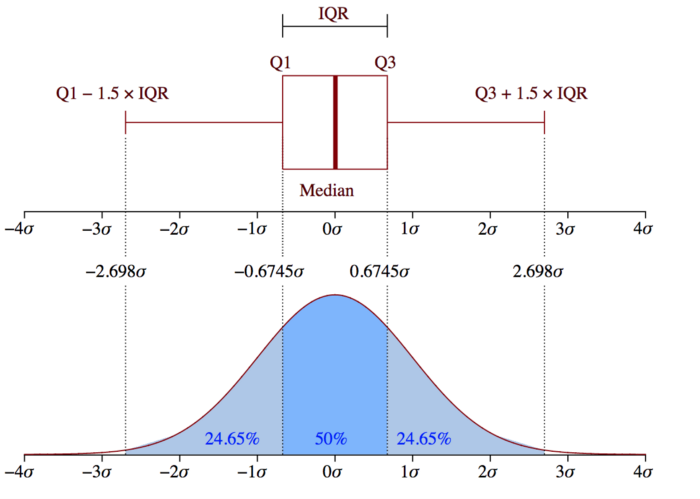
روش 2 – نمودارهای جعبه ای یا Boxplots
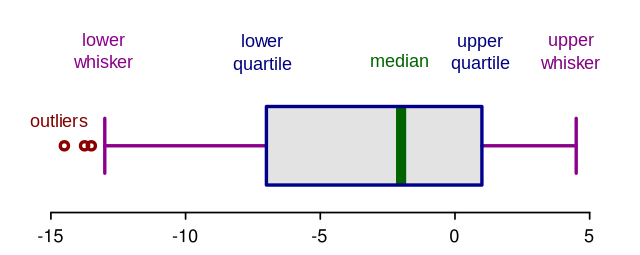
نمودارهای جعبه ای یک تصویر گرافیکی از داده های عددی از طریق چندک آن ها هستند. این یک راه بسیار ساده اما موثر برای تجسم نقاط پرت است. به سبیل های پایین و بالایی به عنوان مرز های توزیع داده فکر کنید. هر نقطه داده ای که در بالا یا زیر سبیل ها نشان داده می شود، می تواند به صورت پرت یا غیر عادی در نظر گرفته شود. در اینجا کد رسم یک نمودار جعبه ای آورده شده است:
|
1 import seaborn as sns |
|
| 2 import matplotlib.pyplot as plt |
کد بالا نمودار زیر را نمایش می دهد. همان طور که می بینید، هر چیزی بالاتر از 75 یا کمتر از حدود منفی 35 را یک امر پرت در نظر می گیرد. نتایج به روش 1 در بالا بسیار نزدیک است.
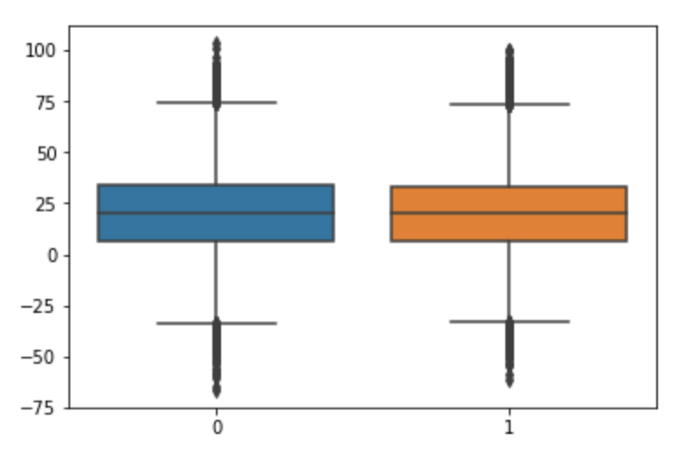
آناتومی نمودار جعبه ای:
مفهوم محدوده بین ربعی (IQR) (Interquartile Range) برای ساخت نمودار های جعبه ای استفاده می شود. IQR مفهومی در آمار است که برای اندازه گیری پراکندگی آماری و تنوع داده ها با تقسیم مجموعه داده ها به چارک ها استفاده می شود.
به عبارت ساده، هر مجموعه داده یا هر مجموعه ای از مشاهدات بر اساس مقادیر داده ها و نحوه مقایسه آنها با کل مجموعه داده به چهار بازه تعریف شده تقسیم می شود. چارک چیزی است که داده ها را به سه نقطه و چهار بازه تقسیم می کند.
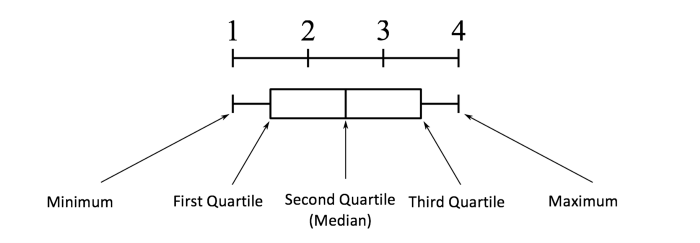
محدوده بین ربع (IQR) مهم است زیرا برای تعریف نقاط پرت استفاده می شود. این تفاوت بین چارک سوم و چارک اول است (IQR = Q3-Q1). نقاط پرت در این مورد به عنوان مشاهداتی تعریف می شوند که در زیر (Q1 – 1. 5x IQR) یا نمودار جعبه ای پایین تر یا بالا تر (Q3 + 1. 5x IQR) یا سبیل بالایی نمودار جعبه ای هستند.
روش 3- خوشه بندی DBScan:
DBScan یک الگوریتم خوشه بندی است که از داده های خوشه ای در گروه ها استفاده می کند. همچنین به عنوان یک روش تشخیص نا هنجاری مبتنی بر چگالی با داده های تک بعدی یا چند بعدی استفاده می شود. سایر الگوریتم های خوشه بندی مانند k میانگین و خوشه بندی سلسله مراتبی نیز می توانند برای تشخیص نقاط پرت استفاده شوند. در این مثال، من نمونه ای از استفاده از DBScan را به شما نشان می دهم، اما قبل از شروع، اجازه دهید برخی از مفاهیم مهم را پوشش دهیم. DBScan دارای سه مفهوم مهم است:
- نقاط اصلی یا Core Points : برای درک مفهوم نقاط اصلی، باید برخی از فرا پارامتر های مورد استفاده برای تعریف کار DBScan را بررسی کنیم. اولین فرا پارامتر (HP) min_samples است. این فرا پارامتر، حداقل تعداد نقاط اصلی مورد نیاز برای تشکیل یک خوشه است. دومین HP مهم eps است. eps حداکثر فاصله بین دو نمونه برای در نظر گرفتن آنها در یک خوشه است.
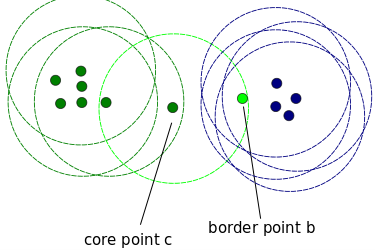
نقاط مرزی یا Border Points: در همان خوشه نقاط اصلی قرار دارند اما بسیار دور تر از مرکز خوشه هستند.
- هر چیز دیگری Noise Points نامیده می شود، این نقاط داده ای هستند که به هیچ خوشه ای تعلق ندارند. آنها می توانند غیر عادی یا نا غیر عادی باشند و نیاز به بررسی بیشتر دارند. حالا بیایید کدی را ببینیم.
|
1 from sklearn.cluster import DBSCAN |
|
|
2 seed(1) |
|
|
3 random_data = np.random.randn(50000,2) * 20 + 20 |
|
|
4 |
|
|
5 outlier_detection = DBSCAN(min_samples = 2, eps = 3) |
|
|
6 clusters = outlier_detection.fit_predict(random_data) |
|
|
7 list(clusters).count(-1) |
خروجی کد بالا 94 است. این تعداد کل نقاط نویز است. SKLearn نقاط نویز را به عنوان (1) برچسب گذاری می کند. نقطه ضعف این روش این است که هر چه ابعاد بالاتر باشد، دقت آن کمتر می شود. شما همچنین باید چند فرض مانند تخمین مقدار مناسب برای eps داشته باشید که می تواند چالش برانگیز باشد.
روش 4- جنگل جداسازی یا Isolation Forest:
Isolation Forest یک الگوریتم یادگیری بدون نظارت است که به خانواده درختان تصمیم گیری تعلق دارد. این روش با تمام روش های قبلی متفاوت است. تمام موارد قبلی در تلاش بودند تا ناحیه نرمال داده را بیابند و سپس هر چیزی خارج از این منطقه تعریف شده را به عنوان یک پرت یا غیر عادی شناسایی می کردند.
این روش متفاوت عمل می کند. این به طور صریح نا هنجاری ها را به جای نمایه سازی و ساختن نقاط و مناطق عادی با اختصاص امتیاز به هر نقطه داده جدا می کند. از این واقعیت استفاده می کند که نا هنجاری ها نقاط داده اقلیت هستند و دارای مقادیر مشخصه ای هستند که بسیار متفاوت از نمونه های معمولی هستند. این الگوریتم با مجموعه داده های ابعادی بسیار بالا کار می کند و ثابت کرد که روشی بسیار مؤثر برای تشخیص نا هنجاری ها است. از آنجایی که این مقاله به جای دانش چگونگی روی پیاده سازی تمرکز دارد، من بیشتر از این به نحوه عملکرد الگوریتم نمی پردازم.
حالا بیایید کد را بررسی کنیم:
| 1 from sklearn.ensemble import IsolationForest | |
| 2 import numpy as np | |
| 3 np.random.seed(1) | |
| 4 random_data = np.random.randn(50000,2) * 20 + 20 | |
| 5 | |
| 6 clf = IsolationForest( behaviour = ‘new’, max_samples=100, random_state = 1, contamination= ‘auto’) | |
| 7 preds = clf.fit_predict(random_data) | |
| 8 preds |
این کد پیش بینی های مربوط به هر نقطه داده در یک آرایه را خروجی می دهد. اگر نتیجه منفی 1 باشد، به این معنی است که این نقطه داده خاص، یک نقطه پرت است. اگر نتیجه 1 باشد، به این معنی است که نقطه داده یک نقطه پرت نیست.
روش 5- جنگل برش تصادفی قوی یا Robust Random Cut Forest:
الگوریتم Random Cut Forest (RCF) الگوریتم بدون نظارت آمازون برای تشخیص نا هنجاری ها است. با مرتبط کردن امتیاز نا هنجاری نیز به خوبی کار می کند. مقادیر پایین امتیاز نشان می دهد که نقطه داده “نرمال” در نظر گرفته می شود. مقادیر بالا نشان دهنده وجود یک نا هنجاری در داده ها است. تعاریف “کم” و “بالا” به کاربرد بستگی دارد، اما رویه رایج نشان می دهد که نمرات بیش از سه انحراف استاندارد از میانگین نمره غیر عادی در نظر گرفته می شوند. جزئیات الگوریتم را می توان در این مقاله یافت.
نکته مهم در مورد این الگوریتم این است که با داده های ابعادی بسیار بالا کار می کند. همچنین می تواند بر روی داده های جریان بی درنگ یا real-time streaming data (ساخته شده در AWS Kinesis Analytics) و همچنین داده های آفلاین کار کند.
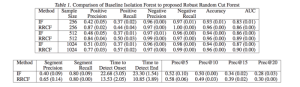
این مقاله برخی از معیار های عملکرد را در مقایسه با جنگل ایزوله (Isolation Forest) نشان می دهد. جدول زیر نتایج حاصل از مقاله است که نشان می دهد RCF بسیار دقیق تر و سریع تر از Isolation Forests است.
مثال کامل را می توانید از لینک زیر ببینید
نتیجه:
ما در دنیایی زندگی می کنیم که داده ها لحظه به لحظه بزرگتر می شوند. ارزش داده ها در صورت عدم استفاده صحیح می تواند به مرور زمان کاهش یابد. یافتن نا هنجاری ها به صورت آنلاین یا آفلاین در مجموعه داده برای شناسایی مشکلات در کسب و کار یا ایجاد یک راه حل فعال برای کشف احتمالی مشکل قبل از وقوع یا حتی در مرحله تجزیه و تحلیل داده های اکتشافی (EDA) برای آماده سازی مجموعه داده برای ML بسیار مهم است./
دیدگاهتان را بنویسید